

Elke organisatie heeft een geformaliseerd proces dat vastlegt wat wordt aangeschaft in de infrastructuur. Ook wel bekend als configuratie management, met een bijbehorende Configuration Management Database (CMDB) als centraal register. Door de veranderingen in technologie en fusies begint dit systeem barsten te vertonen. Daardoor is het zicht op de infrastructuur vertroebeld en worden niet altijd weloverwogen beslissingen genomen.
Misschien moet ik iets uitleggen over de configuratie database, of beter gezegd de veelheid van databases. Een centrale repository, die gebruikt kan worden als betrouwbare bron ontbreekt vaak of is niet volledig. Wel zijn er allerlei verschillende databases, onderdeel van diverse beheeroplossingen die data verkrijgen uit de management interfaces van de infrastructuur. Maar uitwisseling van informatie tussen deze databases i s vaak slecht waardoor de stukjes van de puzzel verspreid zijn. Op de verschillende lagen van it-organisaties kon je dan ook de bekende en altijd aanwezige Excel lijsten tegen die gebruikt worden voor het uitvoeren van de dagelijkse activiteiten. Als deze lijsten worden gedeeld en betrouwbaar zijn is dat niet zo'n probleem. Maar vaak zijn ze onvolledig, achterhaald of irrelevant, eigenlijk dus net als de configuratie database.
Service Knowledge Management
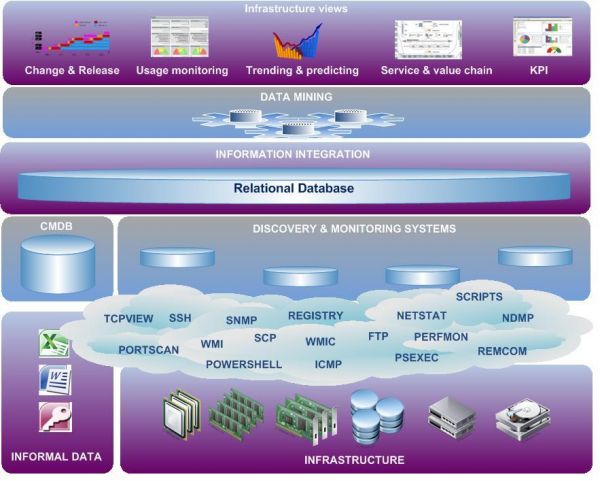
Wie bekend is met ITILv3 weet dat bovenstaande precies is waar Service Knowledge Management om gaat. Door de afnemende afhankelijkheid met de hardware, waarbij zelfs de grenzen van het datacenter vervagen, gaat het nu allemaal om de service. De behoefte aan informatie over de infrastructuur is daarmee echter niet minder geworden. Alleen gaat het hierbij meer om de relaties dan het wat en waar van configuratie items. Het gaat dus om een relationele database, die toestaat om data uit verschillende bronnen, welke niet altijd in eigen beheer hoeven te zijn, te consolideren. Dat maakt het mogelijk om op de metadata van de infrastructuur een soort 'data mining' uit te voeren. Door correlatie van gegevens kunnen zodoende patronen herkend worden die helpen in de besluitvorming.
To Excel or not
Dat klinkt revolutionairder dan het in werkelijkheid is omdat de data vaak al aanwezig is of eenvoudig te verkrijgen vanuit de infrastructuur. Achterliggende idee is hergebruik, transformatie en verrijking van de data die opgesloten ligt in verschillende beheersystemen en Excel sheets. Een tegenovergestelde benadering dus van wat in de praktijk gangbaar is door eerst een product te kiezen en dan het probleem erbij te vinden. Meeste it-organisaties hebben dan ook geen gebrek aan instrumentarium maar tasten nog in het duister over de relaties in de infrastructuur. Dit komt bijvoorbeeld tot uitdrukking bij wijzigingen, die hierdoor niet volledig of ongeautoriseerd zijn en tot verstoringen en extra kosten leiden. Misschien dat release management dan ook beter veranderd kan worden in relatie management.
Application Dependency Mapping
Verschillende leveranciers van Configuration Management oplossingen leveren dan ook een extensie die het mogelijk maakt om deze relaties inzichtelijk te maken. Dit kan vanuit de techniek, waarbij vooral communicatie patronen zichtbaar worden met Application Dependency Mapping. Maar ook handmatig door de organisatorische relaties, welke vaak in de hoofden van mensen of de vele excel sheets zit, vast te leggen in een relationeel model. Een open database(model) die eigen aanpassingen toestaat maakt het mogelijk om een centrale repository te maken. Wie daarin de al aanwezig kennis combineert met gegevens, online verkregen uit de infrastructuur krijgt een orakel dat niet alleen vandaag maar ook morgen beslissingen kan ondersteunen.
Geheim van de keuken
De technieken die gebruikt worden met Application Dependency Mapping hebben grote overeenkomsten met de wijze waarop hackers informatie krijgen. Eenvoudige middelen zoals NETSTAT , TCP suites en dergelijke geven informatie over welke poorten gebruikt worden, met wie applicaties een connectie hebben en de identiteit van een systeem. Correleren van data uit andere management interfaces zoals bijvoorbeeld SNMP en WMI zorgt ervoor dat er relaties gelegd kunnen worden. Helaas kan de effectiviteit hiervan ook beperkt worden door beveiligingsmaatregelen. Ook het feit dat niet alle informatie vanuit de infrastructuur verkregen kunnen worden is een beperking. Combineren van gegevens uit bijvoorbeeld de configuratie database of andere bronnen complementeert dan het beeld.
Value chain
Het groeperen van systemen en applicaties in service ketens op basis van communicatie patronen is de eerste stap naar financiële inzichtelijkheid. Het verrijken van deze informatie met gegevens over gebruik en inzet maakt duidelijk waar de waarde in de infrastructuur zit. Verrassend vaak blijken dan essentiële onderdelen van de infrastructuur niet redundant. Terwijl maatregelen ter verbetering van de beschikbaarheid zich nog weleens richten op onderdelen die veel minder vaak gebruikt worden. Investering in aanvullingen op configuratie management die de inzichtelijkheid verbeteren laten zich dan ook snel terug verdienen.









Een leuk artikel, dat, ondanks enkele gechargeerde stellingnames, zeker een grote kern van waarheid bevat.
Wat ik jammer vindt is dat er vooral gekeken wordt naar een oplossing, en niet naar de oorzaak van de verscheidenheid aan CMDB’s en Excel lijsten.
Het is en blijft blijkbaar moeilijk voor managers / organisaties om keuzes te maken als er meerdere afdelingen samengevoegd worden. Doordat deze keuzes niet gemaakt worden, blijven de diverse repositories naast elkaar bestaan, en moet er weer een dure consultant ingehuurd worden om alle data aan elkaar te knopen en toegankelijk te maken.
Als veel te goedkope consultant kom ik telkens deze problemen tegen. Geen gebrek aan hulpmiddelen, repositories en Excel Sheets (de oorzaak) waardoor niemand het overzicht nog heeft (het resultaat).
Een mogelijke oplossingsrichting die ik probeer te geven is om anders tegen configuratiedata aan te kijken. En juist niet direct een product te kiezen maar eerst naar de behoefte te kijken.
Zodat de ingehuurde consultant/architect niet achteraf vierkante blokjes door ronde gaatjes moet komen slaan.
Als waarschijnlijk nog goedkopere consultant valt me op dat de termen Configuration Management en Change en Configuration Management altijd voor verwarring zorgen.
Bij bedrijven die gedreven zijn vanuit “beheer” staat het Intranet vol met termen vanuit ITIL over configuration management, CMDB etc… en wordt nieuwe ontwikkeling gezien als gedreven vanuit beheer. Met alle gevolgen van dien voor de inrichting van de organisatie.
Bij bedrijven die gedreven zijn vanuit “ontwikkeling” staat het Intranet vol met termen vanuit Agile Development, RUP, etc… over een heel ander soort Configuration Management, CMP en ideale wereld model en wordt nieuw ontwikkeling gezien als de “core” van de IT met alle gevolgen van dien voor de organisatie.
Het zijn 2 totaal verschillende soorten van configuration management met 2 verschillende doelen en verschillende software oplossingen als ondersteuning maar op de een of andere manier eindigt toch maar 1 soort definitie als denkwijze binnen een bedrijf.
@Cogmios
Je hebt een goed punt door te stellen dat er meerdere werelden zijn. Ik ontken ook niet het nut van meerdere databases of andere repositories. Zolang deze maar onderling informatie uit kunnen wisselen om een ‘Babylonische spraakverwarring’ te voorkomen.
Vaak blijkt dit technisch niet mogelijk waardoor gegevens niet up-to-date zijn. En verkeerde informatie leidt vaak tot foute besluiten. In de wereld van beheer wordt dat de menselijke fout genoemd, in ontwikkeling een bug en in de business voortschrijdend inzicht.
Welke naam je eraan geeft is niet belangrijk, wel de schade die het veroorzaakt.
Cultuur speelt een belangrijke rol bij dit soort processen. In onze polder cultuur hebben veel verschillen de groepen, afdelingen en teams ieder hun eigen verantwoordelijkheid.
De verdeling is niet net lineair, maar op verschillende niveaus in de organisatie zitten verschillende aansluitende en overlappende verantwoordelijkheden.
Eenvoudig op het niveau van de gemeenschappelijke verantwoordelijkheid 1 keuze maken en deze vervolgens ook nog door de tijd handhaven is vaak te veel gevraagd.
Gevolg zijn verschillende oplossingen met verschillende doelen die op verschillende momenten in de tijd ingevoerd worden, waarbij afhankelijk van doel en budget de informatie 1-malig opgeslagen wordt of ook werkelijk onderhouden blijft.
Goed artikel omdat het een aantal basiselementen voor een CMDB benadrukt. In de reacties zijn ook een aantal belangrijke punten genoemd.
Mijn visie en ervaring is de volgende:
Een goede CMDB heeft pas zin als er veel informatie in staat (in onderlinge samenhang en compleet). Dat is vaak niet het geval. Uiteraard zul je in projecten moeten faseren en je kan niet alles bijhouden….hierbij gaat het dus om het kiezen van de goede grenzen per onderwerp.
ITers administreren niet…..althans als je mag generaliseren. Dat zit in de cultuur. Dat is natuurlijk een lastige uitgangspositie om informatie bij te houden. Dit vereist een proces implementatie voor de steady state van te voren. Van belang is het dat gebruik van de data zoveel waarde heeft dat een geautomatiseerde administratie realistisch is.
Binnen ICT omgevingen is veel informatie al beschikbaar en in bestanden, echter vaak incompleet, slecht onderhouden of zonder verbanden. Naast een goede methodiek, scope of proces blijft het van belang om bestaande data te koppelen, op te schonen en als basis te gebruiken. Dit is ook de enige manier om uit het vele administreren te blijven of dit tot een minimum te beperken.
Dat zijn volgens mij drie belangrijke componenten om te komen een situatie waarbij het werken met data en gegevens mensen gaat informeren, stimuleren en motiveren.
Opmerkelijk om in de reacties te stellen dat ITIL verouderd is terwijl ISM hier sterk op gelijkt. Dat ITIL een negatieve bijklank heeft gekregen ligt niet zo zeer aan het framewerk maar eerder aan de mensen. Sommige mensen verschuilen zich nu eenmaal liever achter procedures zodat ze zelf niet hoeven na te denken.
Een andere veel gehoorde klacht is dat implementatie van ITIL veel tijd en geld kost, wat bij ISM niet veel anders lijkt. Een levering van 3 tot 4 maanden voor eerste fase en tijd voor tweede fase niet gegeven lijkt me geen out-of-the-box, eerder veel geld out-of-the-pocket implementatie.
In reactie stellen dat er kosten gemaakt moeten worden als ‘beheer’ niet effectief en efficiënt is lijkt me nogal een contradictio in terminis. Ik kan het beheer bijvoorbeel heel effectief invullen door veel mensen in te zetten. Maar ik kan ook het tegenovergestelde kiezen zodat het efficiënt is.
Zoals ik hele verhaal nu lees is het de zoveelste beschrijving maar geen automatisering. Ik geef in deze NumoQuest dan ook gelijk, ga nu eerst eens kijken wat er nodig is. Een bottom-up benadering door de al aanwezige kennis, hulpmiddelen en beschrijvingen te hergebruiken scheelt een boel geld.