

Stel, de provider waar je al jouw bedrijfsapplicaties hebt ondergebracht ondervindt een heftige storing. Het is inmiddels dag zes van de storing en de bedrijfsapplicaties zijn nog steeds offline. De provider is telefonisch en per e-mail volstrekt onbereikbaar en communiceert geen oplostermijn. Als dat het moment is waarop jij je realiseert dat je een plan had moeten hebben voor dit soort scenario’s, ben je te laat. Er zit niets anders op dan te wachten tot de provider de storing weer onder controle heeft en de dienstverlening wordt hervat.
De afgelopen weken heeft een dergelijk situatie zich voorgedaan bij een provider in Nederland. Ik heb diverse klanten van deze provider aan de telefoon gehad, met de paniek doorklinkend in hun stem. Voor deze klanten kon ik alleen iets betekenen als ze zelf over een kopie van de data en de applicaties beschikten, voor de meesten zat er niets anders op dan te wachten en ervan te leren. In dit artikel lees je welke mogelijkheden je hebt als afnemer van IaaS en waar jouw beperkingen liggen.
Er zijn diverse methodieken beschikbaar om de continuïteit van de applicaties te waarborgen in het geval van een storing in de infrastructuur van de provider. Het nadeel van de meeste van deze oplossingen is dat ze de medewerking van de provider vereisen voor de inrichting, het beheer en onderhoud, maar bovenal voor de daadwerkelijke uitwijk. En dat is nou precies het punt: de provider is onbereikbaar.
Private cloud
Idealiter kun je als klant zelf beslissen over de inzet van een disaster recovery (dr)-oplossing en kun je de daadwerkelijke uitwijk ook zelf initiëren. Bij het gebruik van een private cloud (IaaS) zijn er diverse mogelijkheden om een betrouwbare dr-oplossing te implementeren. Denk hierbij bijvoorbeeld aan:
- Stretched virtualisatie clusters (EMC Vplex / NetApp Metro Clusters).
- Storage gebaseerde replicatie in combinatie met geautomatiseerdedr- tooling (EMC Recoverpoint, HP Lefthand in combinatie met VMware vSphere Site Recovery Manager).
- Replicatie op virtualisatie niveau (Veeam Backup & Replication/Zerto Virtual Replication/Novell Platespin Migrate).
Public cloud
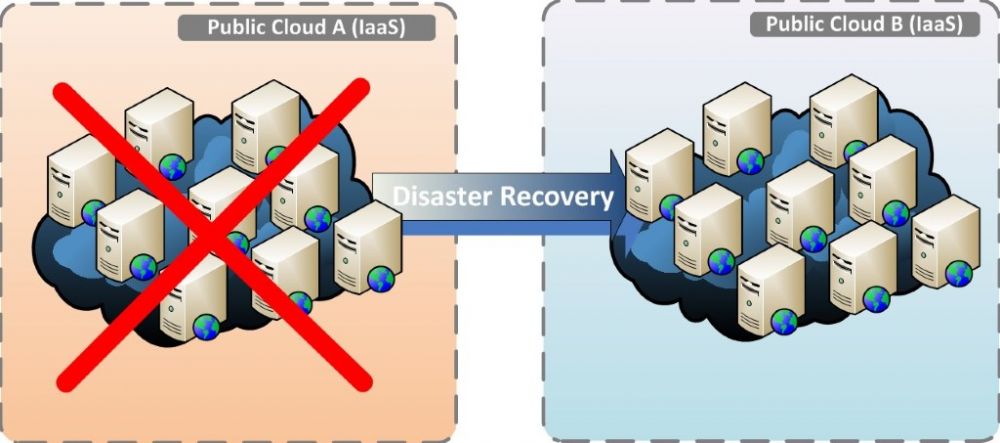
Bij public cloud (IaaS), waar er meerdere klanten op dezelfde fysieke infrastructuur draaien, zijn de mogelijkheden aanzienlijk beperkter en bovendien lastiger te realiseren. De professionelere providers hebben een dr-oplossing in het standaard product portfolio (wees bedacht op goed bedoelde specials). Zijn deze er niet, dan ben je aangewezen op de oplossingen die binnen het controledomein van jou als klant liggen. Meestal behelst dit alles vanaf de virtuele laag tot aan de applicatie. Replicatie op virtualisatie niveau is dan een mogelijkheid. Deze oplossingen zijn echter (op dit moment) nog onvolwassen als het gaat om public cloud (IaaS). Het resultaat is dus dat de disaster recovery in zo’n geval ingeregeld moet worden vanaf de operating system- en applicatie-lagen. Mogelijkheden zijn bijvoorbeeld het inrichten van replicatie op dataniveau en het clusteren van applicaties over meerdere cloud-providers. Dit vereist complexere ontwerpen voor data-synchronisatie en applicatie-clustering.
Wat me bevreemd is dat de meeste gebruikers van (public en private) cloud IaaS diensten ten onrechte denken dat de provider zorg draagt voor dr-diensten terwijl toch duidelijk uit het sla blijkt dat dit niet het geval is. De inrichting van dr is klant-specifiek en vereist een gedegen kennis van de infrastructuur van de klant. Providers die hierin excelleren hebben bij de inrichting van hun infrastructuur de juiste keuzes gemaakt en daarmee het fundament gelegd voor een goede recovery.
Mijn advies: leer van de situaties zoals die zich recent hebben voorgedaan en test of jouw huidige dr-plan voldoet aan de eisen van vandaag. Het is daarbij prima om te vertrouwen op de dr van je provider, maar test dan tenminste wel minimaal elke zes maanden. Besteed dan speciaal aandacht aan recente wijzigingen, gemaakt aan de applicaties en infrastructuur. Een veel gemaakte fout is dat wijzigingen aan de infrastructuur niet doorwerken in de dr-oplossing, met catastrofale gevolgen bij een werkelijke uitwijk.
Zelf volledig in control zijn? Richt dan een dr-oplossing in die binnen je controledomein ligt. De continuïteit van de onderneming ligt op de weegschaal. Handel snel maar vooral zorgvuldig.









Ewout, ja, ik heb nog wat verder nagedacht over IaaS en DR en hier zijn mijn laatste twee centen over het onderwerp.
– Amazon Webservices en Windows Azure hebben standaard technieken ingebouwd voor fail-over naar een ander data center. Testen daarvan is nogal moeilijk al zijn er nu wat API calls mogelijk waarmee je een fail kunt simuleren. Pest met echte rampen is dat ik sterk twijfel of het echt goed zal functioneren en zoals gezegd, het is slechts op een aantal lagen (database,storage,dns), en als het massaal gebeurd door een ramp moet je nog maar zien dat het werkt zoals beloofd. Testen op grote schaal… de eerste moet nog plaatsvinden op het publieke domein.
– Het is evident dat SDI en Virtualisatie in combinatie met images en DNS het maken van een DR plan (voor Iaas wat eigenlijk altijd op basis van virtualisatie gaat) makkelijker maken.
– Een DR plan is altijd op een schaal van niets tot perfect (en denk aan classificatie) waarbij de kosten niet lineair oplopen, het is zoeken naar de balans van acceptabel en betaalbaar. Bij een ramp zullen mensen aan de bak moeten en zal er downtime bestaan en er zullen onverwachte zaken optreden.
– Een aantal scenario’s bij rampen is oneindig. Het failliet gaan, gehackt worden of afgesloten worden van je provider is er in ieder geval één van, dus in het geval van IaaS mag je niet bouwen op één provider. Laat dit een startpunt zijn van ieder bedrijf dat Iaas, Paas of SaaS afneemt.
– Salesforce in de volle breedte inzetten (Saas en Paas) neemt een vervelend probleem met zich mee. Een goed DR plan is nagenoeg niet mogelijk, de vendor lock-in is bijna net zo sterk als bij het adopteren van SAP (kan een goede en gegronde beslissing zijn), omdat het platform adopteren functioneel maatwerk inhoudt wat je volgens mij niet kunt verplaatsen naar een alternatief. Controle houden over je data betekent goede exports maken van je data op basis van een goed domein model zodat je in geval van een ramp in ieder geval een migratie mogelijk maakt. Daarbij moet ik wel opmerken dat Salesforce zijn product goed onder controle lijkt te hebben. Zo ver ik weet kun je salesforce niet on-premises draaien en ben je qua ramp afhankelijk van Salesforce.
Reza & Henri
Ik denk dat ik jullie alle 2 in 1 kan beantwoorden: Meten is weten!
Natuurlijk zijn er mogelijkheden om op opslag gebied een ‘data reductie’ te doen maar heel vaak werkt dat maar één kant op, iets met ‘journal sizes’ ofzo. Heb al eens het voorbeeld van Nirvanix genoemd, de stress-test voor cloud migratie en Henri is juist door te zeggen dat er vele oorzaken zijn waardoor je moet uitwijken. Wel grappig dat hij dingetjes naar voren welke ik naar ik meen al in een opinie van bijna 2 jaar geleden genoemd heb:
https://www.computable.nl/artikel/opinie/cloud_computing/4546441/2333364/cloud-beheersbaar-maar-niet-beheerbaar.html
Elk nadeel heeft dan ook zijn voordeel want soms werkt een uitvallende cloud oplossing heel genezend doordat de ‘IT regiseurs’ erachter komen dat die ‘Nieuwe IT’ uiteindelijk gewoon oud gedrag vertoont waardoor in één keer alle ‘Schaduw IT’ inzichtelijk wordt. Johan brengt de term Schadefreude in maar we hebben in het Nederlands daar volgens mij gewoon het woord leedvermaak voor want vaak wordt pas weer aandacht aan dingen gegeven als het bij de buren mis gaat maar of het gras ook altijd groener is bij de buren;-)