
Datacenters zijn anno 2019 uitgegroeid van organische netwerken met een verzameling switches voor het verbinden van servers in een stuk of wat racks tot grootschalige, capaciteitsrijke en uiterst complexe fabrics met een grote capaciteit en gestapelde gevirtualiseerde overlay-netwerken. De huidige routeringsprotocollen voor het beheer van deze infrastructuren zijn oorspronkelijk alleen voor kleinschalige mesh-netwerken ontwikkeld. Ondanks alle pogingen van de afgelopen jaren om de functionaliteit van deze protocollen zover mogelijk op te rekken, blijven ze behoorlijk ‘old school’. En lopen ze steeds meer uit de pas met de moderne netwerkbehoeften.
Clos-netwerken (ook wel ‘spine-leaf’-netwerken genoemd) zijn momenteel de dominante architectuur. Ze maken gebruik van een Layer 3-protocol als underlay. Voor de routering voor de underlay van de ip-fabric hanteren ze soms een interior gateway protocol (igp), maar vaker een border gateway protocol (bgp). RFC7938 beschrijft hoe zo’n fabric geschikt kan worden gemaakt voor ‘grootschalige’ datacenters.
Voor kleine datacenters met maximaal duizend switches levert het gebruik van bgp prima resultaten op, mits er sprake is van voldoende tooling en Opex. De problemen nemen echter zienderogen toe wanneer de omvang groeit. Er zijn een hoop lapmiddelen voor de huidige routeringsprotocollen beschikbaar, maar er is een beter alternatief.
Als voorbeeld; stel je gebruikt ebgp en kent aan elke switch een privaat autonomous system number (asn) toe. Vervolgens connecteer je een paar extra switches… Dan ontstaat er een probleem. Er zijn namelijk slechts 1.023 16-bits private asn’s beschikbaar. De oplossing zou zijn om gebruik te maken van private 32-bits asn’s. Lapmiddel numero uno.
Een volgend probleem met het huidige ontwerp: stel je het IPv4-adresplan voor dat nodig is voor alle verbindingen in een kleinschalig netwerk met veertig leaf-switches en vier spine-switches. Volgens een snelle rekensom resulteren veertig leaf-switches en vier spine-switches in veertig verbindingen per spine voor alle leaf-switches. Dat betekent in totaal 160 verbindingen tussen switches, dus minimaal 160 keer een /31 IPv4-subnet. Als we dit toepassen op een zogenaamd 5-stage clos en vier super-spines toevoegen die elk twintig van deze fabrics verbinden, komen we uit op 160x20x4=12.800 /32 IPv4-subnetten. Zie je de uitdaging?
Deze twee voorbeelden zijn nog maar het topje van de ijsberg van de problemen. Je zult legio van dit soort uitdagingen tegenkomen en een beroep moeten doen op je MacGyver-toolbox.
De oplossing
Als het aanpassen van de huidige protocollen en architecturen die in datacenters worden gebruikt niet de oplossing is, wat dan wel? Traditionele igp’s moeten bijna net zo ingrijpend worden aangepast als bgp om werkelijk ‘datacenter native’ en schaalbaar te worden. Bovendien zijn ze in gewijzigde vorm wellicht niet langer interoperabel met bestaande versies.
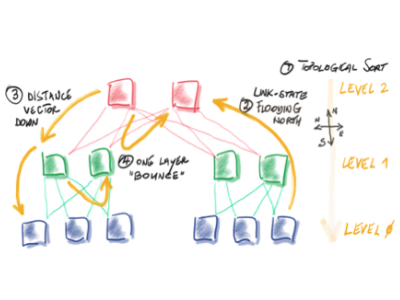
Maar er is licht aan de horizon in de vorm van een nieuw ‘ip fabric native’-protocol: routing in fat trees. rift in het kort. Dit nieuwe routeringsprotocol voor clos-underlays combineert het beste van link state-routering, kortste pad-routering en routering op basis van distance/path-vectoren. Rift voegt daar mogelijkheden aan toe zoals zero touch provisioning, blast radius-indamming, automatische balancering van de bandbreedte, ecmp, high availability en snelle mobiliteit. Dit protocol is ontwikkeld om te voldoen aan de eisen die een ip-fabric aan routeringsprotocollen stelt, plus de wens om die infrastructuur zo eenvoudig mogelijk te kunnen beheren.
Vanuit het oogpunt van routering maakt rift gebruik van northbound link state flooding-routering en southband distance vector-routering. Dit resulteert in aanmerkelijk snellere convergentie, de noodzaak van minder routes op de leaf-switch (in normale situaties, dus zonder uitval van verbindingen in de fabric), zeer uitgebreide ondersteuning voor ecmp en automatische flooding-reductie.
‘Leuk en aardig’, denk je nu misschien, ‘maar is dat nou alles?’ Nou, nee. Het beste moet nog komen. Zo biedt rift volledige zero touch provisioning. Dat komt omdat IPv6 neighbour discovery (nd) voor de adressering kan worden gebruikt. Met nd is het niet meer nodig om ip-adressen voor verbindingen te configureren. Het protocol is loop-free ingericht, met andere woorden: alle paden binnen de fabric kunnen tegelijk worden gebruikt. Het betekent ook dat rift automatisch dataverkeer balanceert op basis van de beschikbare northbound capaciteit. Het volstaat om default routes aan de leafs toe te kennen, en als er een storing optreedt is de blast radius minimaal. Rift is daarnaast ontwikkeld met in gedachte opkomende technologieën zoals segment routing (sr).
Lichtgewicht
Een ander voordeel is dat rift lichtgewicht is en ook op servers kan draaien. Dit maakt multi-homing mogelijk met load balancing van de bandbreedte en pakweg integratie voor de automatische en dynamische toewijzing van ip-adressen op servers in architecturen zoals vm- en containeromgevingen.
Als je nu denkt ‘mijn handen jeuken om dit binnen mijn netwerk te testen en toe te passen’, dan hoef je niet langer te wachten. Rfit is nog werk in uitvoering in de IETF RIFT werkgroep, maar het specificatiedocument nadert zijn voltooiing.
Het goede nieuws is dat sommige leveranciers al over werkende code beschikken, zodat je aan de slag kunt gaan met testen. Je hebt daarvoor geeneens hardware nodig. Er is ook een open source-implementatie (in Python).
Gaat rift alle problemen in het datacenter oplossen? Wie weet. Eén ding is echter zeker: het biedt een oplossing voor een hoop van de huidige, traditionele problemen die binnen grootschalige datacenters spelen.
Mijn advies voor nu luidt: begin met testen, deel je ervaringen en lever input op het werk dat in de rift-werkgroep in ietf gebeurt. Schroom niet om contact te zoeken met de auteurs van het document dat de specificaties van rift beschrijft of met mij als je suggesties of aanvullingen hebt.








