

De Panama Papers wordt ook wel het grootste journalistieke onderzoeksproject ooit genoemd. Journalisten kregen het voor elkaar om 2,6 terrabyte aan gelekte documenten te doorzoeken. Dat is eigenlijk onbegonnen werk, maar het is ze toch gelukt. En wel dankzij de graph database; een andere benadering van data-opslag dan we tot nu toe gewend waren. De populariteit groeit in rap tempo en dat is niet voor niets. Maar wat maakt dit type database nu eigenlijk zo bijzonder?
De belangrijkste en meest waardevolle eigenschap van een graph database is de mogelijkheid om verbanden te leggen. In een relationele database wordt alles in een tabelstructuur opgeslagen. Anders dan je zou denken, leg je in een relationele database dus juist geen relaties vast. Relaties worden gecreëerd door af te spreken dat een ID in de ene tabel verwijst naar een ID in een andere tabel. Een foreign key kan ervoor zorgen dat de rdbms controleert of de beide ID’s overeenkomen. Een relatie is echter rijker dan een verwijzing. Een relatie tussen een man en een vrouw is niet alleen ‘getrouwd’, maar heeft bijvoorbeeld ook een trouwdatum en een typering zoals ‘in gemeenschap van goederen’. Dergelijke verrijkingen moet in een rdbms worden opgelost met technische constructies zoals tussentabellen.
Netwerk met verschillende actoren
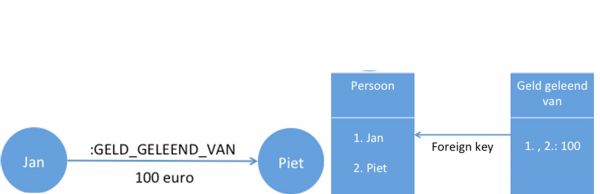
Een graph database werkt dus eigenlijk zoals een netwerk dat je in je gedachten of op een whiteboard zou maken. In dit netwerk heb je verschillende actoren, zowel personen als zaken, die ook wel nodes worden genoemd. Tussen de nodes worden connecties gemaakt. Deze connecties hebben een richting en kunnen worden verrijkt met data. De relatie die wordt gelegd in de graph database is ook echt fysiek aanwezig.
Bijvoorbeeld; persoon A (node) heeft geld geleend (connectie) van (richting) persoon B (node), weergegeven in nevenstaande figuur. In een relationele database is bijvoorbeeld alleen vast te leggen dat persoon A geld heeft geleend. En los daarvan, dat persoon B geld heeft uitgeleend. Het zou in deze database een hoop extra stappen vereisen om erachter te komen wat de connectie tussen persoon A en B is.
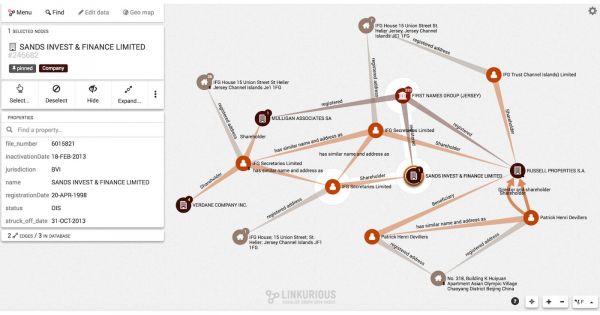
Bij de Panama Papers is er ook zo’n netwerk gemaakt. In dit netwerk zijn er veel verschillende soorten nodes, waaronder: bedrijven, personen, e-mails, declaraties en bankafschriften. Deze zijn allemaal aan elkaar gelinkt en een relatie was eenvoudig te benoemen (persoon x heeft contract y getekend, persoon a is aandeelhouder van bedrijf b). Door dit in een graph database weer te geven, ontstond er een volledig netwerk van personen en zaken die iets met elkaar te maken hebben. Hierdoor kon relatief eenvoudig worden ontdekt dat veel bekende personen zijn betrokken bij belastingontduiking.
In een gewone database zou je deze relaties er wellicht ook uit kunnen halen, maar dat is veel ingewikkelder dan met een graph database. Je moet zelf de verbanden leggen en hoe meer nodes er bij betrokken zijn, hoe meer verbanden er zijn en hoe ingewikkelder het netwerk wordt. De paden tussen aan elkaar gelinkte nodes zijn soms erg lang. Uiteindelijk verlies je dan het overzicht.
Agile en flexibel
Daarnaast mag de data in een graph database flexibel zijn. Met andere woorden; niet iedere node of relatie hoeft dezelfde eigenschappen te hebben. Dit in tegenstelling tot een relationele database, waar iedere tabel exact dezelfde kolommen moet hebben.
Met een graph database kan je in principe dus sneller beginnen, omdat je niet eerst alle data gelijk hoeft te trekken. Je begint met een basis datamodel, dat gemakkelijk uit te breiden is. Dit past goed bij de Agile werkomgevingen en grote hoeveelheden ongestructureerde data van tegenwoordig. Dit is zowel een zegen als een vloek. Hoe gevarieerder je data is, des te meer moet je applicatie rekening houden met deze variatie.
Ontwikkeling
Hoewel de graph database dus een duidelijke meerwaarde heeft ten opzichte van de relationele database als het gaat om netwerken, wordt in het overgrote merendeel van de bedrijfsapplicaties nog steeds de relationele database toegepast. Applicaties die wel een graph database gebruiken, zijn vaak net gelanceerd. Dat maakt ze meteen innovatief, maar ook wat kwetsbaarder. De graph database is nog sterk in ontwikkeling. Er komen nog steeds vernieuwingen en de producten zien zelf nog meer de kracht van hun eigen product. Dat maakt dat de producten nog in beweging zijn en niet zo sterk zijn uitontwikkeld als de bestaande rdbms’en.
Daarnaast vereist een graph database andere kennis. Waar alle developers tegenwoordig goed overweg kunnen met SQL, vergt de graph database een andere manier van denken. De database-mindset moet als het ware veranderen. Ook is het gebruik van een graph database vaak duurder. Er zijn gratis oplossingen, zoals de open-source editie van marktleider NEO4j, maar als je het echt binnen een organisatie wilt toepassen en mogelijkheden als back-ups en schaalbaarheid nodig hebt, zal je een betaalde variant moeten kiezen.
Dit alles in tegenstelling tot de relationele database; deze technologie is bedacht in de jaren zestig, gebouwd in de jaren zeventig en groot geworden in de jaren tachtig. Het is een bewezen technologie, die wordt toegepast in grote en kleine applicaties en die betrouwbaar en stabiel is.
Juiste keuze
Toch is het een kwestie van tijd voor we de graph database steeds vaker gaan gebruiken. De technologische ontwikkelingen van tegenwoordig vragen om andere oplossingen.
Wanneer je voor een database moet kiezen, is het dus goed om je verbeelding te gebruiken. Als je geïnteresseerd bent in de relaties tussen de data, en gecompliceerde patronen van interactie ziet tussen verschillende actoren, dan kies je voor een graph database.
Big data zorgt ervoor dat er steeds meer aan elkaar is gelinkt en relaties belangrijker worden. Vanuit steeds meer bronnen willen we data met elkaar verbinden. Onder andere om kennis uit te abstraheren en onderzoek te doen. Het is juist de graph database die betekenis geeft aan deze big data.



