

De resultaten van een penetratietest worden geclassificeerd in lage, gemiddelde en hoge risico’s. Vaak wordt er voor gekozen dat de lage risico resultaten ook de laagste prioriteit hebben om opgelost te worden. Maar lage risico’s vormen wel degelijk een beveiligingsrisico. Wat te doen?
Een penetratietest (of it-beveiligingstest) wordt gebruikt om de kwetsbaarheden in een applicatie, systeem of netwerk bloot te leggen. De resultaten van een penetratietest worden vastgelegd in een rapportage. Vast onderdeel in dergelijke rapportages is een beschrijving van de gevonden kwetsbaarheden. Om de ernst van de gevonden kwetsbaarheden aan te geven, wordt vaak gebruikgemaakt van een classificatie in lage, gemiddelde en hoge risico’s.
Onder ‘hoge risico’s’ verstaan we kwetsbaarheden die zonder veel inspanning van de aanvaller tot grote schade kunnen leiden. Denk hierbij aan SQL-injectie en ontbrekende autorisatiecontroles. ‘Gemiddelde risico’s’ leiden tot minder schade of zijn moeilijker of slechts onder bepaalde omstandigheden uit te buiten. Typische voorbeelden zijn cross-site scripting en session-fixation. ‘Lage risico’s’ leveren vanuit technisch oogpunt weinig risico op of zijn zeer lastig uit te buiten. Lage risico’s die we vaak aantreffen zijn het lekken van versie-informatie, de aanwezigheid van testpagina’s in een productieomgeving, het tonen van uitgebreide foutmeldingen en het verkeerd coderen van uitvoer.
Het is niet uitzonderlijk dat een rapportage van een penetratietest op een webapplicatie enkele hoge risico’s, een handvol gemiddelde risico’s en meer dan tien lage risico’s bevat. Het oplossen van gevonden risico’s heeft vaak veel voeten in de aarde. In veel gevallen is er te weinig tijd en budget om alle risico’s op te lossen. Er wordt dan gekozen om hoge risico’s en gemiddelde risico’s eerst op te lossen en de lage risico’s later aan te pakken. Maar later betekent soms nooit. In sommige gevallen is het beleid om uberhaupt geen lage risico’s op te lossen.
Het oplossen of verminderen van risico’s is altijd een afweging tussen investeringskosten en potentiële schade. Dit is een afweging die gemaakt moet worden door de eigenaar van een applicatie of systeem en niet door de penetratietester. Wat echter bij deze afweging niet uit het oog verloren moet worden, is dat lage risico’s wel degelijk een beveiligingsrisico vormen. Sterker nog, lage risico’s kunnen voor een aanvaller bijzonder nuttig zijn en kunnen het vinden van serieuzere kwetsbaarheden aanmerkelijk bespoedigen.
Een praktijkvoorbeeld
In dit artikel beschrijf ik een onderzoek naar een webapplicatie van ontwikkelaar Acme (fictieve naam). Voor dit onderzoek was echter maar zeer beperkte tijd beschikbaar. Er was geen broncode beschikbaar die gebruikt kon worden om kwetsbaarheden te achterhalen. Drie lage risico’s die we in de applicatie aantroffen zorgden er echter voor dat we binnen zeer korte tijd kwetsbaarheden konden vinden waarmee volledige toegang tot de database, de broncode, de ssl/tls private keys met bijbehorende passphrases en de web server hadden. In dit artikel betoog ik daarom dat het oplossen van lage risico’s het voor een aanvaller veel moeilijker kan maken om kwetsbaarheden te vinden. Dit zou meegenomen moeten worden in een afweging om lage risico’s al dan niet te mitigeren.
Directory indexing
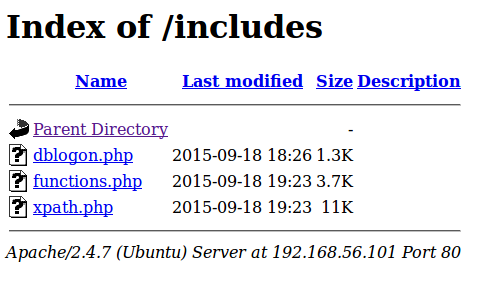
Bij een webapplicatie-onderzoek maken we standaard gebruik van een aantal tools om configuratiefouten op webservers te detecteren. De tool Dirbuster spoort verborgen en vergeten bestanden en directory’s op een webserver op. Dirbuster vraagt geautomatiseerd een grote lijst met mogelijke bestands- en directorynamen op, waarna handmatig bekeken kan worden of hierin gevoelige informatie of kwetsbaarheden te vinden zijn.
In het uitgevoerde onderzoek vonden we met Dirbuster een aantal directory’s met namen als ‘include’, ‘proxy’, ‘scripts’ en ‘plugins’. Bij het opvragen van deze directory’s zien we dat we een lijst te zien krijgen met bestanden; een zogenaamde ‘directory listing’ (zie het volgende figuur voor een voorbeeld):
De ‘include’ en ‘global’ directory’s bevatten een groot deel van de bestanden die de broncode van de applicatie vormden. Echter, omdat deze bestanden de extensie .php hadden werden deze doorgegeven aan de php-interpreter, en was het niet mogelijk om ze te downloaden.
In de ‘proxy’ directory troffen we echter een testscript aan. Dit script kon gebruikt worden voor debugging en trachtte een bestand op te vragen. Het script bleek echter een kwetsbaarheid te bevatten, waardoor het door middel van path traversal (dat wil zeggen het toevoegen van ../../../) mogelijk was om bestanden van het bestandssysteem op te vragen. Deze werden door middel van de php-functie fpassthru() weergegeven in de pagina. In combinatie met de eerder gevonden directory listings en een eenvoudig shell-script was het hiermee mogelijk om een groot deel van de broncde en configuratiebestanden van de webserver te downloaden.
Het ingeschakeld hebben van directory listings is op zichzelf een laag risico. Immers, kennis van de bestandsnamen en directorynamen leidt niet direct tot het lekken van persoonsgegevens of bedrijfsinformatie. Het stelde ons in dit geval echter in staat om debug-functionaliteit te vinden die eenvoudig te misbruiken was.
Uitgebreide foutmeldingen
De mogelijkheid om de broncode te doorzoeken is uitermate nuttig voor het vinden van kwetsbaarheden. Misschien wel net zo nuttig is een applicatie die bij een onverwachte situatie exact vertelt waar hij mee bezig is en wat er fout gaat.
De webapplicatie in kwestie maakte veelvuldig gebruik van SQL om gegevens uit de database te lezen en te wijzigen. In de broncode zagen we dat geen gebruik gemaakt werd van geparametriseerde query’s. In plaats daarvan werd gebruikgemaakt van stringconcatenatie (aaneenschakeling) in combinatie met escaping van potentieel gevaarlijke karakters. Deze manier van bevragen van de database is uiterst foutgevoelig en vergroot de kans op SQL-injectie aanzienlijk. Immers, voor elke invoerparameter moet voorkomen worden dat deze gebruikt kan worden om de structuur van een database-query aan te passen.
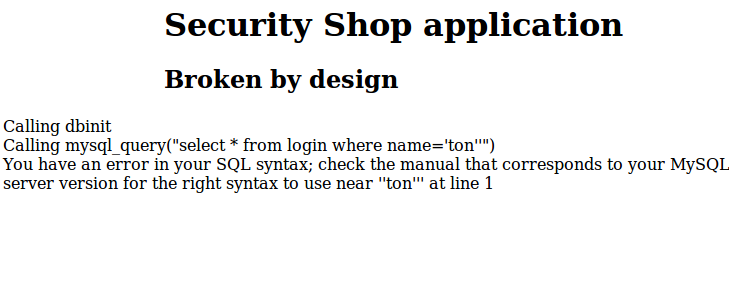
Wanneer een SQL-query syntactisch niet correct is, kan het database managementsysteem deze niet uitvoeren. Deze zal daarom een foutmelding geven en aangeven waar de syntactische fout in de query zich bevindt. Standaard worden deze foutmeldingen teruggeven aan de webapplicatie en het is de taak van de webapplicatie om deze foutmeldingen – niet – te tonen aan de eindgebruiker. In sommige gevallen (en ook in de onderzochte applicatie) worden deze foutmeldingen echter wel aan de gebruiker getoond (zie afbeelding als voorbeeld).
In de broncode van de onderzochte webapplicatie was de code voor de constructie, escaping en uitvoer van SQL-query’s verspreid over verschillende klassen, methoden en bestanden. Hierdoor was het lastig om de exacte plaats in de webapplicatie te bepalen waar SQL-injectie mogelijk was. Op basis van de broncode waren echter eenvoudig potentiële kandidaten te achterhalen. Doordat de applicatie uitgebreide foutmeldingen gaf, was het zeer eenvoudig te controleren of een potentiële kandidaat daadwerkelijk kwetsbaar was. Het injecteren van een enkel en/of dubbel aanhalingsteken leidde tot een foutmelding dan en slechts dan als deze niet voorzien werd van escaping. In het geval van een foutmelding werd zelfs de volledige query getoond. Hierdoor was niet alleen duidelijk dát een query kwetsbaar was, maar ook hoe deze uit te buiten was. Vervolgens was het kinderspel om door middel van sqlmap informatie van onze keuze (denk aan persoonsgegevens en wachtwoordhashes) uit de database te lezen en te wijzigen.
Uitgebreide foutmeldingen geven de aanvaller inzicht in de werking van de applicatie, maar geven niet direct de mogelijkheid om gevoelige informatie te achterhalen of wijzigen. Het is daarom op zichzelf een laag risico. Echter, het stelde ons in staat om zonder veel moeite kwetsbare SQL-statements te vinden.
Versie-informatie
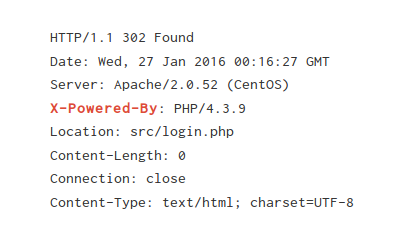
Misschien wel één van de meest bediscussieerde lage risico’s is het lekken van versie-informatie. Hiermee bedoelen we dat de webapplicatie, de webserver, of een library middels een versienummer prijsgeeft wat de exacte versie van de gebruikte software is.
Zelfs een maatwerkapplicatie maakt gebruik van een groot aantal softwarecomponenten. Denk aan de webserver, de interpreter, het besturingssysteem van de webserver en het databasemanagementsysteem. Veelal wordt gebruikgemaakt van library’s voor het parsen van xml, het afhandelen van asynchrone requests, het genereren van pdf’s, het schalen van afbeeldingen of het bewerken van templates. Al deze componenten kunnen kwetsbaarheden bevatten en moeten daarom up-to-date gehouden worden.
Wanneer een softwarecomponent een update ontvangt, wordt het versie-nummer opgehoogd. Als de versie-nummers van gebruikte softwarecomponenten voor een aanvaller op te vragen zijn, kan vaak eenvoudig achterhaald worden of de software kwetsbaarheden bevat. Andersom kunnen met zoekmachines op basis van versienummers eenvoudig kwetsbare systemen gevonden worden. Er bestaat zelfs een zoekmachine die toegewijd is aan het indexeren van systemen op het internet die hun versie-informatie prijsgeven: Shodan.
In het onderzoek in kwestie konden we door middel van het bekijken van de ‘plugins’-directory achterhalen welke third-party library’s gebruikt werden. Ook konden we door het aanroepen van de code van deze plugins eenvoudig achterhalen welke versie gebruikt werd. Een van deze plugins bleek een publiek bekende remote code execution kwetsbaarheid te bevatten. Door deze kwetsbaarheid was het mogelijk om commando’s op het systeem uit te voeren en de resultaten daarvan te inspecteren. Zo konden we bijvoorbeeld ssl/tls private keys uitlezen. De bijbehorende passphrases vonden we in de logging die op dezelfde server aanwezig was. Ook was het mogelijk om de web server te gebruiken om andere systemen in de ‘demilitarized zone’ (dmz) aan te vallen.
Conclusie
De vraag rijst of lage risico’s zoals de bovengenoemde wel als laag risico gekwalificeerd moeten worden wanneer de gevolgen zo groot zijn. Naar mijn mening is dat wel degelijk zo: de lage risico’s zorgen er slechts voor dat de hoge risico’s makkelijker te vinden zijn. Feit blijft dat drie relatief onschuldige lage risico’s ertoe leidden dat een aanvaller eenvoudig en effectief grote gaten kon vinden. Natuurlijk is de eerste prioriteit dan om die grote gaten te dichten. Het zou echter te kort door de bocht zijn om daarna de lage risico’s te negeren.
Vanuit het defense-in-depth principe dienen meerdere verdedigingslagen opgeworpen te worden om te voorkomen dat een aanvaller toegang kan krijgen tot gegevens waarvoor hij niet geautoriseerd is. Defense-in-depth zorgt er niet alleen voor dat een aanvaller moeilijker toegang krijgt, maar ook dat aanvallen beter gedetecteerd kunnen worden. Een aanvaller kan namelijk veel minder gericht zoeken naar kwetsbaarheden en zal daarom veel meer (detecteerbare) ruis veroorzaken.
Daarbij zijn lage risico’s in sommige gevallen zeer eenvoudig op te lossen. Directory indexing en lekkende versie-informatie in http-responseheaders kunnen met een enkele regel in de configuratie van de webserver of de proxy voorkomen worden. Het tonen van uitgebreide foutmeldingen kan vaak globaal afgevangen worden in de applicatieconfiguratie. Dit suggereert dat de tijd die het oplossen van deze risico’s vraagt niet altijd opweegt tegen de tijd die besteed zou worden om te besluiten of de risico’s uberhaupt opgelost moeten worden.
Het negeren van lage risico’s kan vanuit een business-perspectief de juiste keuze lijken. Hou daarbij echter in het achterhoofd dat een aanvaller ook blij zal zijn met die keuze.
Ton van Deursen, senior security consultant bij Madison Gurkha









Een risico – naar mijn opinie – is de classificatie van de kans van optreden vermenigvuldigd met de daaruit (mogelijk) voortvloeiende schade. En in hoeverre daarin veranderende wetgeving tot een nieuwe indexering leidt kan ik niet voorspellen maar er zit een kern van waarheid in het feit dat de kleine incidenten van gisteren morgen weleens een probleem kunnen zijn.
Voor de rest is het verhaal onzin, cyber-defense gaat namelijk niet om een statische verdediging van loopgraven maar de mobiliteit. En waarom zou ik een actieve aanval doen als de passieve veel meer resultaat levert?