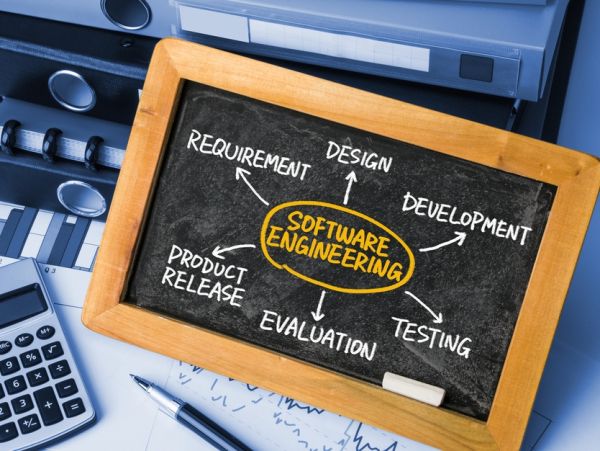

Organisaties moeten steeds sneller veranderen om aan de veranderende vraag van klanten te blijven voldoen. Dit stelt hoge eisen aan de ontwikkeling van applicaties. Klanten eisen niet alleen snelheid maar ook extreme gebruikersvriendelijkheid. Werkt bijvoorbeeld een webwinkel niet naar behoren, dan is er snel een alternatief voorhanden. Agile softwareontwikkeling sluit goed aan op deze veranderbehoefte en is inmiddels in een groot deel van de organisaties doorgedrongen.
Om aan de groeiende hoeveelheid (test)werk te blijven voldoen neemt het aandeel en het belang van testautomatisering toe. Echter, wil testautomatisering daadwerkelijk ondersteunend zijn aan de veranderende organisatie, dan stelt dat andere eisen aan mensen en (test)processen. Het goed begrijpen van de impact van testautomatisering is daarom belangrijk. Architectuur kan mede helpen, doordat het op een gestructureerde manier inzicht kan geven. Het maakt het mogelijk om een gestructureerd plan te maken, waarbij alle belangrijke onderdelen worden meegenomen.
Het startpunt van architectuur is een set van principes; richtinggevende uitspraken die aangeven wat belangrijk is. Omdat deze principes voor een belangrijk deel hetzelfde zijn voor iedere organisatie hebben wij een generieke set van principes voor testautomatisering geïdentificeerd. Vanuit onze kennis en ervaring van testen, testautomatisering en architectuur hebben we beschreven wat wij denken dat belangrijk is. Deze principes zijn voor ons tevens een startpunt voor een boek dat we schrijven over testautomatisering, waarin de principes en de architectuur verder uitwerkt worden en tegelijkertijd dienen als ‘paraplu’ voor de rest van het boek. De volgende principes belichten respectievelijk het organisatie- en het informatievoorzieningsperspectief.
Organisatieprincipes
Principe 1: Testautomatisering past bij de doelstellingen en volwassenheid van de organisatie.
Testautomatisering is geen doel op zich; het is een manier om organisatiedoelstellingen te ondersteunen. De mate waarin het bijdraagt verschilt per organisatie. Het vraagt een investering, die moet worden gerechtvaardigd, en het vraagt vooral een organisatieverandering. Zo leidt het bijvoorbeeld tot een verschuiving van de taken van de testengineer, die meer software-ontwikkeltaken krijgt. Testautomatisering veronderstelt ook een minimum volwassenheidsniveau, met name op het gebied van software-ontwikkeling. Een goede analyse van de organisatiecontext en de kosten en baten van testautomatisering (business case) is daarom noodzakelijk. Volwassenheidsmodellen helpen reële ambitieniveaus te definiëren en geven meer zicht op de noodzakelijke inspanning.
Principe 2: Testautomatisering is gebaseerd op een heldere visie, beleid en architectuur.
De implementatie van testautomatisering moet niet lichtzinnig worden opgevat. Het is een relatief complex onderwerp dat vraagt om het maken van allerlei keuzes. Denk hierbij aan positionering van testautomatisering in de organisatie of de opzet van testautomatisering. Het maken van weloverwogen keuzes helpt om testautomatisering toekomstvast in te richten. Er moet ook voorkomen worden dat testautomatisering een ‘one-size-fits-all’ aanpak wordt; je kunt er ook in doorschieten. Door het opstellen van een testvisie wordt duidelijk welke doelstellingen testautomatisering vooral dient en welke risico’s het vooral adresseert. Testbeleid legt de belangrijkste uitgangspunten vast over hoe er met testen wordt omgegaan en wat de rol van testautomatisering daar in is. Testarchitectuur beschrijft de inrichting van testen op hoofdlijnen zoals het te hanteren proces en de te gebruiken tools.
Principe 3: Testautomatisering houdt rekening met de menselijke maat.
De mens is de allesbepalende factor en dat is ook zo bij testautomatisering. De term ‘automatisering’ lijkt er wellicht op dat de mensen minder belangrijk worden, maar niets is minder waar. De activiteiten verschuiven en stellen juist hogere eisen aan mensen. Iedereen die een betrokkenheid heeft bij testen moet begrijpen waarom testautomatisering belangrijk is en wat hun betrokkenheid inhoudt. Er zal dus goed moeten worden gekeken naar de impact op de rollen die benodigd zijn bij de testprocessen en bijbehorende competenties. Enerzijds verdwijnt repeterend werk en zal de nadruk komen te liggen op de analyse van de testresultaten. Anderzijds zal het belang van de rol van testengineer toenemen. Een veranderkundig perspectief op testautomatisering is daarom erg belangrijk.
Principe 4: Testautomatisering vraagt een weloverwogen afweging tussen risico en inspanning.
Testen en het automatiseren van tests kost tijd en alles doortesten kost in veel gevallen teveel tijd. Het is daarom belangrijk de testinspanning te richten op de zaken die de meeste aandacht vragen, of op die delen die de grootste risico’s lopen. In het verleden werd er niet altijd doorgerekend of testen voldoende toegevoegde waarde bood. Testautomatisering kost echter meer inspanning, waardoor het belangrijker is om de waarde vooraf goed te bepalen. Het is daarom belangrijk om een rekenmodel te gebruiken waarin alle factoren die risico en inspanning bepalen zijn benoemd. Dit rekenmodel zal intelligent moeten zijn zodat de onderdelen die waarvoor automatisering waardevol is onderscheiden worden van onderdelen waarvoor dat het niet geval is. Een globalere versie van het rekenmodel moet ook worden gebruikt bij het opstellen van de business case voor testautomatisering.
Informatievoorzieningsprincipes
Principe 5: Testautomatisering is modelgebaseerd.
Er worden in het testproces allerlei modellen en gegevens gebruikt die betrekking hebben op de applicatie die wordt getest. Deze modellen kunnen direct in het testproces worden toegepast, ondermeer voor het automatisch genereren van testscripts en de verwachte testresultaten. Dit zorgt ervoor dat de ontwikkel- en beheerinspanning wordt geminimaliseerd, dat inconsistenties zoveel mogelijk worden voorkomen en dat aanpassingen in de applicatie zo min mogelijk vragen om aanpassingen in de testscripts. Deze kunnen dan opnieuw worden gegenereerd. Het in gestructureerde, modelgebaseerde vorm vastleggen van functionaliteit stelt hogere eisen aan het analyse- en ontwerpproces. Functionaliteit wordt bij voorkeur in pseudocode beschreven.
Principe 6: Gegevens voor testautomatisering worden expliciet beheerd.
Gegevens spelen een belangrijke rol in testautomatisering. Omdat de kwaliteit van processen in sterke mate afhankelijk is van de kwaliteit van de gegevens vragen deze laatste expliciete aandacht, en dat geldt dus ook voor de gegevens die worden gebruikt bij testautomatisering. Aandacht voor gegevensbeheer (ook wel: data governance) betekent onder meer het expliciet maken van taken en verantwoordelijkheden. Wie is bijvoorbeeld verantwoordelijk voor de testware na het afronden van het project? Als er geen goede afspraken zijn dan is er een reële kans dat de testware niet consistent is en daarmee onbruikbaar. Versie- en configuratiebeheer op de betrokken gegevens is daarom essentieel.
Principe 7: Testautomatisering houdt expliciet rekening met informatiebeveiliging.
Klanten verwachten dat organisaties op een zorgvuldige manier met hun gegevens omgaan en dat deze niet in handen komen van onbevoegden. Wet- en regelgeving zoals de ‘Wet Bescherming Persoonsgegevens’ stelt hieraan ook expliciete grenzen. Testautomatisering dient daarom ook specifieke aandacht te hebben voor informatiebeveiliging. Gegevens die gebruikt worden bij het testen mogen niet herleidbaar zijn naar individuen (zoals klanten). Gegevens bevinden zich ook bij voorkeur binnen Europa en niet onder invloed van specifieke overheden, bijvoorbeeld in het kader van de ‘Patriot Act’. In meer algemene zin dient aandacht te zijn voor informatiebeveiligingsrisico’s en maatregelen, en het daarvoor noodzakelijke beleid.
Principe 8: Testautomatiseringstools zijn noodzakelijk maar niet leidend.
Testautomatisering vraagt ondersteuning door tools; deze dienen de automatisering mogelijk te maken en uit te voeren. Het is echter belangrijk om te beseffen dat tools slechts ondersteunend zijn; de echte uitdagingen zijn met name organisatorisch van aard. De tools dienen vooral de doelstellingen en de risico’s goed te ondersteunen, wanneer ze meer dan dat doen dan sluiten ze niet goed aan. Voor sommige organisaties en applicaties kan een set van eenvoudige tools voldoende zijn, terwijl in andere situaties een meer uitgebreide toolset noodzakelijk is. De keuze voor testtools zou daarom gebaseerd moeten zijn op de testvisie en -beleid. Dure tools zijn niet per definitie beter.
Aanzet
We hebben in dit artikel een aanzet gegeven voor de zaken waarvan wij denken dat ze belangrijk zijn bij het inrichten van testautomatisering. Een architectuurbenadering draagt volgens ons bij aan een beter begrip en inzicht. Testarchitectuur is dan ook een belangrijke competentie in het kader van testautomatisering. Wij zijn benieuwd of anderen de door ons geschetste principes herkennen zodat we ze kunnen aanscherpen.
Wie zijn de auteurs?
Danny Greefhorst is directeur van ArchiXL en Computable-expert voor het topic Architectuur. Jos van Rooyen is principal consultant bij Bartosz, en Computable-expert voor het topic Development. Marcel Mersie werkt als projectleider en consultant bij Bartosz.









Prima stuk. Een tweetal zaken die ik nog mis:
Testautomatisering hoeft niet alleen maar via de user interface te worden aangevlogen. Liever niet, wat mij betreft.. UI-gedreven geautomatiseerde scripts zouden alleen moeten worden gebruikt wanneer de UI het testobject is, of wanneer er echt geen andere opties voorhanden zijn. In het algemeen: valideer functionaliteit op de juiste laag in de applicatie, dat houdt het overzichtelijk en onderhoudbaar.
En als aanvulling op #3: geautomatiseerde tests zijn in principe niets anders dan checks. Een echte test vraagt menselijk inzicht, creativiteit en beoordelingsvermogen. Testautomatisering is daarmee wel een toevoeging aan het testproces, en een steeds belangrijker onderdeel naarmate release- en testcycli steeds korter worden, maar testers zullen niet verdwijnen. Ik ben het er helemaal mee eens dat de rol van testers wel verandert. De functioneel tester die strak volgens TMap of ISTQB zijn testplannen en testscripts opstelt en afwerkt gaat het niet overleven.
Mooi stuk!
Ik denk wel dat het belangrijk is om tegenwoordig een onderscheid te maken over wat voor een vorm van geautomatiseerd testen het gaat.
TDD, BDD, unit testen, acceptatietesten…dit zijn allemaal testen die tegenwoordig door de ontwikkelaars worden gedaan. Performance testen, Load testen… is ook allemaal testautomatisering.
Functionele testautomatisering, waar ik me mee bezig hou, is nog niet in iedere organisatie geïmplementeerd.
Mijn streven is dat hetgeen wat ik maak kan worden ingezet door iedereen. Alle testers of functioneel beheerders kunnen scripts maken voor testautomatisering. De vertaling van script naar “code” is technisch en wordt door de navigator gedaan.
Een boeiend opiniestuk waaraan ik naast enkele kritische opmerkingen ook enkele constructieve discussiepunten wil toevoegen (en dat verdeeld over 3 reacties).
Wat mij allereerst opvalt is de nadruk op verandering in de introductieparagraaf. Moet er naast de veranderbehoefte bij mensen en organisaties niet in de eerste plaats worden gewezen op een zijnsbehoefte; de behoefte dat dingen blijven zoals ze zijn. Een mooi voorbeeld is hier de introductie van Windows 8, dat geen succes werd, omdat een aantal cruciale zaken in de gebruikersinterface was veranderd. Naast behoefte aan nieuwe functionaliteit is er vooral ook behoefte aan functionaliteit die blijft werken zoals het al jaren (of sinds de vorige sprint) naar tevredenheid werkt en waarvoor de zogenaamde regressietest is uitgevonden.
In de tweede plaats valt de wetenschappelijke aanvliegroute van testautomatisering op; tot uiting komend in een principe als: Testautomatisering is modelgebaseerd. Wordt hier niet een mate van (berekenbare) voorspelbaarheid gesuggereerd die bedrijfsapplicaties niet in zichzelf hebben?
Maar ook bij het omschrijven van een principe als richtinggevende uitspraak kunnen vraagtekens worden gezet. Met een variant op een uitspraak van Jan Schaefer zou je kunnen stellen : “In richtinggevende uitspraken kun je niet wonen”. Persoonlijk begrijp ik principes dan ook liever als mogelijkheidsvoorwaarden.
Maar hoe je principes ook begrijpt; het blijft een boeiend, maar ook ingewikkeld vraagstuk.
Vergelijk bijvoorbeeld de volgende 10 omschrijvingen van dit begrip:
http://www.encyclo.nl/begrip/principe
Tegenover het modelgebaseerd zijn van testautomatisering zou ik testautomatisering kortweg willen omschrijven als:
1. datagedreven, aangezien de benodigde testdata gescheiden wordt gehouden van de draaischema’s/testscripts; bovendien speelt testdata een actieve rol bij het genereren van testscripts,
2. keywordgedreven, aangezien de keywords van een specifieke testtool zijn ondergebracht in testscripttemplates,
3. businessgedreven, aangezien onderscheid wordt gemaakt tussen functionele, platformonafhankelijke, bedrijfsdraaischema’s en onderliggende, vanuit templates ingevoegde fysieke (dus platformafhankelijke) testscripts, en
4. templategedreven, aangezien testscripttemplates, gecombineerd met testgegevens op andere tabbladen, herhaald in de testscripts ingevoegd worden op basis van vermelde proefgevalnummers.
Kortom, tooling waarmee bedrijfstesters, functioneel testers, technische testers, testnavigatoren, functioneel beheerders, technische applicatiebeheerders, enz. optimaal kunnen samenwerken. Het behoeft nauwelijks toelichting dat je de basis voor dit soort tooling in een spreadsheetprogramma als Excel wilt hebben (wat het gebruik van “tabblad” bij punt 4 al deed vermoeden).
Het idee van testscripttemplates heb ik uitgewerkt in mijn eerste reactie op Computable:
https://www.computable.nl/artikel/opinie/development/3199097/1277180/geautomatiseerd-testen-is-een-abctje.html
en het onderscheid tussen bedrijfstesters, functioneel testers en technische testers in een reactie op:
https://www.computable.nl/artikel/opinie/development/4619996/1277180/de-rol-van-de-tester-verandert.html#4623367
Uitgaande van de testtooling, zoals beschreven in de vorige reactie, wil ik nu inzoomen op de mogelijkheidsvoorwaarden voor het opzetten van regressietesten.
In mijn optiek zijn er 3 zaken die het opzetten van regressietesten – het testen of reeds gerealiseerde functionaliteit niet is omgevallen als gevolg van de oplevering van nieuwe functionaliteit – sterk bemoeilijkt, zeer tijdrovend maakt of zelfs onmogelijk maakt. Al deze zaken hebben overigens te maken met het testen binnen servicegeoriënteerde architecturen.
In de eerste plaats wordt het opzetten van regressietesten sterk bemoeilijkt door het gebruik van systeemdatums in welke betrokken deelapplicatie dan ook. Met het gebruik van systeemdatums in plaats van jobdatums of transactiedatums in software help je de mogelijkheid voor het opzetten van regressietesten vakkundig om zeep; het ontneemt je als tester namelijk de mogelijkheid om te kunnen tijdreizen. Maar ook de opkomst van cloud computing is een reden temeer om het gebruik van systeemdatums in bedrijfsapplicaties niet toe te staan (met uitzondering hooguit voor het moment van initiatie van een proces of dienst).
Hiermee samenhangend wordt het opzetten van regressietesten bemoeilijkt doordat betrokken deelapplicaties niet altijd in fase zijn geactualiseerd; het gaat bijvoorbeeld mis als de reguliere processen in deelapplicatie A voor het laatst gedraaid hebben in augustus 2014, terwijl in deelapplicatie B de prolongatieprocessen voor 2016 al hebben gedraaid. Dit verschijnsel wordt versterkt door het feit dat testomgevingen voor bedrijfsapplicaties vaak gedeeld moeten worden door meerdere testers en soms ook bouwers. Voor het opzetten van goede regressietesten is het dus noodzakelijk te beschikken over eigen testomgevingen voor alle betrokken bedrijfsapplicaties, en te beschikken over de eerder genoemde testtooling waarmee alle betrokken applicaties – soms draaiend op verschillende platforms – in fase kunnen worden geactualiseerd. Want batchprocessen blijven belangrijk in moderne bedrijfsapplicaties; alle verschuiving naar realtime dienstverlening ten spijt.
Ten derde kan het opzetten van regressietesten – bestaande uit soms honderden proefgevallen – zeer tijdrovend zijn als de verwachte testresultaten (ofwel de uitvoervoorspellingen) – die je uiteraard wel geautomatiseerd wilt controleren – ondergebracht moeten worden in de gebruikte testtool. Op dit punt gaat het opiniestuk mijns inziens flink onderuit als wordt gesteld:
“Deze modellen kunnen direct in het testproces worden toegepast, ondermeer voor het automatisch genereren van testscripts en de verwachte testresultaten. “ .
Dat automatisch genereren van testscripts spreekt mij aan; niet dus vanuit modellen, maar vanuit testscripttemplates, zoals eerder al aangegeven. Het idee dat verwachte testresultaten ook uit modellen gegenereerd kunnen worden is een bewering die op geen enkele wijze kan worden waargemaakt. Conform mijn eerder gemaakte opmerking over de vermeende voorspelbaarheid van bedrijfsapplicaties.
Dat gezegd hebbende is het dus een heidens karwei om de uitvoervoorspellingen van honderden proefgevallen – wellicht op verschillende regressiemeetmomenten – in de gebruikte testtool over te nemen, teneinde ze geautomatiseerd te kunnen controleren. Een flinke tijdwinst kan dus worden geboekt als die eerste stap kan worden overgeslagen!
Dat werk ik uit in de volgende reactie.
Een belangrijk issue bij het opzetten van regressietesten is de geautomatiseerde controle van de uitvoervoorspellingen.
Het overnemen van uitvoervoorspellingen in een testtool is een tijdrovend karwei; een flinke tijdwinst kan worden geboekt als deze stap kan worden overgeslagen. De eerder beschreven testtooling in combinatie met het vrij verkrijgbare Notepad++ levert een zeer effectieve methode om regressietesten inclusief de controle van de proefgevallen volledig geautomatiseerd uit te voeren.
Het principe is eenvoudig:
Maak op een ‘willekeurig’ moment in de procesgang, bijvoorbeeld direct na het uitvoeren van een proces of transactie of een ‘willekeurige’ opeenvolging van processen en transacties, een dump van alle relevante databasebestanden naar gelijknamige tekstbestanden, waarbij de naamgeving van deze tekstbestanden tevens een indicatie bevat voor het moment waarop ze zijn aangemaakt (versienummer, mutatiedatum in het draaischema, etc.).
Door nu bij een volgende uitvoering van de regressietest de versienummers van de aan te maken tekstbestanden te verhogen, bijvoorbeeld 01 naar 02 of 01a naar 01b, kan vervolgens met een actiewoord “vergelijk ascii bestanden” de opeenvolgende versies van database/tekstbestanden volledig geautomatiseerd worden vergeleken.
Zodra een verschil wordt geconstateerd stopt de test met de melding:
Er zijn verschillen gevonden tussen
Bestand een: F:……..DBbestandA_04-04-2016_01
Bestand twee: F:……..DBbestandA_04-04-2016_02
Verschil(len) zijn gevonden in:
regel 417
regel 632
regel 635
regel 702
regel 970
Wil je de test stoppen?
Op dit moment kan via de knop Toon bestanden Notepad++ geopend worden met de 2 vergeleken bestanden. Via de optie Plugins > Compare > Compare zijn nu visueel de verschillen heel snel op te zoeken.
Worden geen verschillen gevonden, dan loopt de test gewoon door.
Verschillen die geconstateerd worden tussen de nieuwe databasesituatie, die ontstaat na een oplevering ivm. bouwaanpassingen, en de vorige, kunnen duiden op omgevallen functionaliteit, maar kunnen ook betrekking hebben op nieuwe, gewenste functionaliteit.
Op het moment dat alle proefgevallen in een databasesituatie zijn gecontroleerd met de reguliere raadpleegschermen en akkoord zijn bevonden is het wel zaak om het versienummer van deze situatie duidelijk vast te leggen en de tekstbestanden voor deze situatie veilig te stellen in een extra map.
Bij iedere volgende oplevering hoeven alleen de geconstateerde verschillen gecontroleerd te worden (en dat levert bij veel proefgevallen en veel nieuwe opleveringen van bouw veel tijdwinst op).
Verschillen die geconstateerd worden kunnen betrekking hebben op:
1. reeds aanwezige proefgevallen en ongewijzigde functionaliteit
2. reeds aanwezige proefgevallen en gewijzigde of nieuwe functionaliteit
3. reeds aanwezige gevallen die niet als proefgeval dienen, bijvoorbeeld bij gebruik van (geanonimiseerde) bestanden uit exploitatie of produktie
4. nieuw toegevoegde proefgevallen en ongewijzigde functionaliteit
5. nieuw toegevoegde proefgevallen en gewijzigde of nieuwe functionaliteit
Het is duidelijk dat alleen de verschillen als gevolg van punt 1 (de omgevallen functionaliteit) sowieso gemeld worden bij bouw; de overige verschillen kunnen juist wenselijk zijn!
De hierboven beschreven aanpak is zeer goed toepasbaar binnen zowel waterval als agile/scrum-projecten.
Tot zover deze zolderopruiming; waar een vakantie al niet goed voor is…