

Voor een centraal datacenter is backup en recovery doorgaans goed geregeld! Maar hoe zit het met de bijkantoren? Is het daar ook zo goed geregeld? En voor zover dat niet het geval is, wat is daar aan te doen? In dit artikel een aanpak die misschien niet het meest voor de hand liggend is, maar in de praktijk wel zeer effectief blijkt te zijn!
Veel bedrijven hebben in hun kleinere bijkantoren de nodige servers opgesteld waarbij de backup veelal geregeld is via tapes of dvd’s. Een medewerker van dat bijkantoor wisselt elke dag de tape of dvd.
In een groter bijkantoor wordt er vaak gebruik gemaakt van een klein san en data replicatie. Het streven hier is om minimaal één keer per 24 uur alle gewijzigde data gekopieerd te krijgen naar het centrale datacenter.
De grens tussen een kleiner en een groter bijkantoor ligt bij ongeveer honderd medewerkers, drie à vier fysieke servers en een twintig tot 25 vm’s.
Tot zover lijkt er niet zoveel aan de hand. Immers, een stuk hardware wat de geest geeft of – erger nog – gestolen wordt, is binnen een paar uur wel weer aan de praat te krijgen.
Maar dan begint het eigenlijk pas:
- Wat zijn ook alweer de stappen bij het terugzetten van het besturingssysteem (os), de applicatie(s) en de data?
- Waar is die usb-stick of de dvd met de laatste versie van het server image?
- Hoe zit het met de laatste versie van de backup? Is die betrouwbaar en waar ligt de tape?
- Zijn die twee ook bruikbaar in combinatie met die nieuwe raid-controller?
- Voor de grotere bijkantoren: hoe lang duurt het voordat alle data overgezet is vanuit een van beide data centers? Wat was ook alweer de procedure om dat voor elkaar te krijgen?
Immers, pas als de applicaties volledig in bedrijf zijn kunnen de mensen op het bijkantoor weer aan de slag. Er mag dan ook nauwelijks enige twijfel bestaan over de betrouwbaarheid en snelheid van een recovery procedure!
De twee kpi’s die hier maatgevend zijn, zijn RTO (Recovery Time Objective) en RPO (Recovery Point Objective). De eerste kpi, de RTO, gaat over de maximale recovery tijd: de maximale tijd om de uitgevallen delen zodanig te herstellen dat de normale bedrijfsvoering hervat kan worden. De tweede kpi, de RPO, gaat over data verlies: de maximale, toegestane tijd tussen de laatste, goed werkende backup en het moment van uitval.
Hoe het ook kan
De kern achter het verbeteren van de RTO is het terugdringen van de recovery tijd rondom het os, de applicatie en de data.
Bij het verbeteren van de RPO is de situatie iets anders. Daar is het zaak op zoek te gaan naar iets waardoor er per dag meerdere keren een backup of een replicatie gemaakt kan worden. Hoe hoger de backup en replicatie frequentie, hoe beter de RPO.
De essentie van de beoogde oplossing is een techniek die, zeker bij internationaal opererende bedrijven, bekend staat als wan-acceleratie. Met deze techniek worden de prestaties en beschikbaarheid van applicaties merkbaar beter en consistenter. In dat kader werkt backup-en-recovery niet anders dan een gewone applicatie.
Uiteraard zullen de resultaten van geval tot geval enigszins variëren. Maar in de praktijk blijkt dat zelfs als er gebruik gemaakt wordt van de-duplicatie op, bijvoorbeeld, een filestore van EMC of NetApp, dan nog is er met de inzet van wan-acceleratie een winst te boeken die ligt tussen de 70 en 80 procent. Dat wil zeggen dat de duur van een data replicatie nog maar 20 tot 30 procent bedraagt in vergelijking met een situatie zonder wan-acceleratie. Daardoor kan er per dag meerdere keren een backup of replicatie lopen met als gevolg een sterk verbeterde RPO!
Bij het terugzetten van de data mag je vergelijkbare prestatie verbeteringen verwachten. Doordat de recovery actie nu nog maar een 30 procent bedraagt van wat het was, wordt ook de RTO aanzienlijk verbeterd!
Voor de kleinere bijkantoren gaat het nog verder met de inzet van een zogenaamd stateless replicatie mechanisme. Dat is een mechanisme wat het best valt te omschrijven als het maken van snapshots op basis van de data die op enig moment daadwerkelijk gebruikt wordt. Wijzigingen in deze snapshots worden binnen een bepaalde, gegarandeerde tijd weggeschreven naar de centrale storage omgeving in het datacenter. Deze tijd ligt in ordegrootte van secondes waardoor de RPO beweegt richting die van twin datacenters!
De RTO voor het server- en applicatie deel van de recovery procedure is in dit geval beter dan die van de grotere bijkantoren, doordat het stateless replicatie mechanisme ook gebruikt wordt bij het ophalen en starten van het os en de applicaties. Hierdoor hoeven gebruikers niet te wachten tot alle data teruggezet is; ze kunnen weer aan de slag zo gauw het os en de applicaties gestart zijn.
De techniek
De technologie achter wan-acceleratie is gebaseerd op data- en transport streamlining. Dat regelt de data reductie door caching en compressie. Caching wordt gebruikt om alleen nieuwe data de lijn op te sturen. Voor bestaande data wordt er gebruik gemaakt van verwijzingen naar data die op een eerder moment naar disk of geheugen is weggeschreven. Datgene wat uiteindelijk de lijn op gaat wordt overigens eerst gecomprimeerd met een LZH-algoritme.
Transport streamlining regelt de QoS en het verbeteren van de TCP-window size waardoor de nadelige effecten van netwerk latency tot een minimum beperkt blijven. Hierdoor worden onder andere het aantal “’application turns’ sterk verminderd. De term ‘application turns’ heeft betrekking op het aantal slagen tussen een cliënt en een server wat nodig is om een bepaalde hoeveelheid data verwerkt te krijgen; hoe lager, hoe beter.
Voor de invulling wordt er gebruik gemaakt van tenminste één accelerator in het datacenter en een voor elk bijkantoor. In het kader van het verbeteren van de RTO en RPO blijft het hierbij voor de grotere bijkantoren.
Voor de kleinere bijkantoren wordt dit aangevuld met minimaal één storage gateway in het datacenter. In dat geval wordt er in de bijkantoren een wan-accelerator ingezet met een ingebouwde ESX-laag. Met deze combinatie worden vanuit het san een of meer LUN’s geprojecteerd naar elk van de bijkantoren, waardoor een ieder beschikt over zijn eigen stukje san uit het data-center.
Vervolgens worden er vanaf dat san een of meer vm’s overgehaald en opgestart. In een dergelijk scenario kunnen de gebruikers weer aan het werk zodra de vm’s gestart zijn; wachten op het terugzetten of repliceren van de data is in dit geval niet nodig. Het pre-fetch algoritme in de storage gateway en de wan-acceleratie zijn samen zo efficiënt en effectief dat de gebruikers slechts een minimale vertraging zullen ervaren bij een eerste start van de applicatie en de uitvoering van een eerste transactie.
Ondanks dat de ESX-laag geïntegreerd is in de wan-accelerator op de bijkantoren blijft het mogelijk deze ESX-laag en bijbehorende vm’s volledig in beheer te nemen vanuit de centraal ingeregelde vSphere, vCenter en wat dies meer zij.
De business case

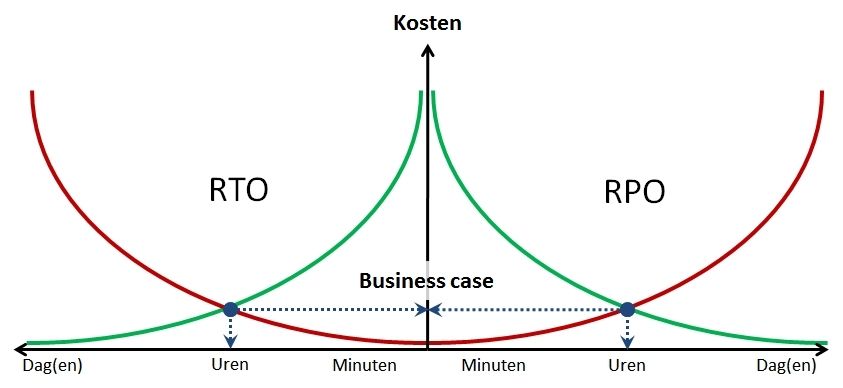
Als je deze twee eerder genoemde kpi’s, de RTO en RPO, uitzet tegen kosten, dan blijkt in de praktijk dat het gebruik van twin datacenters de duurste oplossing is met de beste resultaten. Door de hoge mate van redundantie en automatische failover zijn beide kpi’s (bijna) nul.
Voor de meeste bijkantoren geldt het omgekeerde. In vergelijking met twin datacenters zijn de infrastructurele kosten niet echt hoog. Daar staat tegenover dat de RTO en RPO eerder dagen dan uren zijn, waardoor de productie verliezenexponentieel oplopen.
In nevenstaande afbeelding is dit grafisch weergegeven uitgaande van een groter bijkantoor. De groene lijnen representeren de kosten voor een bepaald niveau van RTO en RPO. De rode lijnen representeren de productieverliezen. Hier valt dus duidelijk wat te verbeteren!
Zoals te zien in deze afbeelding is de business case erop gebaseerd dat je met een minimum aan kosten de RTO en RPO zodanig verbeterd dat dit ruimschoots opweegt tegen de kosten van productieverlies bij een server uitval.
Voor de kleinere bijkantoren is de business case iets anders (en beter!) door het eerder beschreven stateless replicatie mechanisme. Lokale backup’s zijn nu niet meer nodig waardoor de kosten voor backup licenties en de uren rondom het beheer van tapes, dvd’s en usb-drives komen te vervallen.
In het verlengde daarvan zijn er nu ook mogelijkheden om de gevolgschade door bedieningsfouten van gebruikers te beperken. Bijvoorbeeld door een eerdere versie van een adviesrapport terug te zetten, wat door de betreffende adviseur per ongeluk gewist was. Iets wat zeker voor een kleiner bijkantoor niet altijd vanzelfsprekend is (geweest!).
Bijkomend voordeel van een dergelijke aanpak is de verbeterde beveiliging van de data. Door de manier van data opslag is de content van een snapshot niet te herleiden naar de bron data. Met andere woorden, zelfs al zou de accelerator gestolen worden en al zou iemand in staat zijn om de content van een snapshot te bestuderen, dan nog is niet te bepalen wat de gevonden content voorstelt.









Nu is het mijn beurt om iets over WC-eend te roepen, hoewel klok en klepel misschien meer op zijn plaats is. Deduplicatie en compressies zijn tenslotte opties die in veel back-up software zit maar over het algemeen alleen de tijd voor de back-up verbeteren en omgekeerd bij herstel niet zoveel voordeel leveren. Hetzelfde geldt voor de incremental, differental en synthetic back-up technieken welke allemaal prachtig zijn om het back-up window te verkleinen maar weinig helpen bij herstel. En zeker is het netwerk de ‘last mile’ in het verhaal maar een procentuele verbetering van 80% over een T1 lijn lijkt me nog steeds een druppel op de gloeiende plaat. Daarbij weet ik bijna wel zeker dat je geen dedicated bandbreedte hebt, zeker niet tijdens de kantooruren waardoor je dus een te rooskleurig beeld schetst.
@Ewout:
Bedankt voor je reactie. 🙂
Ik heb weinig of geen kennis en ervaring met de werking van de-duplicatie en compressie algoritmes bij backup programma’s. Ik beschrijf hier slechts de ervaring met o.a. data reductie bij de WAN accelerators van – inderdaad – Riverbed.
Voor zover interesse – in de oorspronkelijke versie van dit artikel is een overzicht opgenomen met resultaten uit de *praktijk*; uitgesplitst naar een aantal veel gebruikte applicaties en protocollen. Daarnaast is in deze versie ook iets meer achtergrond informatie over de werking van data reductie terug te vinden. De link naar deze versie: http://moonen.me/2015/05/hoe-backup-en-recovery-voor-bijkantoren-te-verbeteren/
Van een VM image hebben is er ongeveer 10% nodig van de inhoud van de boot “disk” om de VM te kunnen starten – de winst door data reductie is hierin niet meegekomen. Bij een koude start is deze winst nog steeds 30-50%. Alles bij elkaar lijkt me dat toch meer dan een druppel op een gloeiende plaat – zelfs bij een T1 verbinding.
@Will
Als eerste wijs ik op het ontbreken van garanties aangaande de RTO bij cloud based back-up oplossingen, dit simpelweg doordat er geen QoS (netneutraliteit) is. Er is dus een bepaalde lock-down aangaande dedicated lijnen en WAN kosten zijn redelijk hoog, een reductie op het verkeer zelf is economisch voordeliger. Je opsomming aangaande bare-metal restore en ook je reactie aangaande VM’s begrijp ik niet, wat heb ik aan een boot disk zonder bedrijfsapplicaties en data?
Betreffende software installatie is het handiger om een lokaal distributiepunt (NAS?) welke centraal beheerd wordt te gebruiken. En deze kun je misschien ook gebruiken voor de back-up van de client welke ik mis in je verhaal terwijl deze procentueel gezien een groter volume aan data hebben en deduplicatie ratio’s van 80% hier niet ongewoon zijn;-)
Voor zover nog niet bekend: een accelerator heeft disken aan boord waar de meest gebruikte data opgeslagen is. Bij een accelerator met een ESX laag heeft deze data betrekking op onderdelen van het OS, de applicaties en diens data.
Met dat op de achtergrond is de werking alsvolgt:
Vanaf de eerste dag dat een dergelijke accelerator in bedrijf is, wordt bijgehouden wat het gedrag van het OS, de applicaties en de data is. Dit patroon met bijbehorende content wordt vastgelegd op de disken van de accelerator.
Bij een herstart wordt deze data gebruikt om, in “samenspraak” met de storage gateway in het datacenter, die onderdelen de lijn over te halen die minimaal nodig zijn om te starten, maar niet (meer?) op de lokale disken staan. Met deze aanpak staan korte tijd later zowel het OS, de applicaties en data klaar voor gebruik.
Zolang gebruikers de applicaties niet starten gaat de accelerator verder met het actualiseren en overhalen van de rest van de data op basis van het patroon wat eerder is vastgelegd op de locale disken. Zodra gebruikers zich melden verdwijnt dit proces naar de achtergrond en krijgen de gebruikersacties voorrang.
Deze aanpak maakt dat je nauwelijks meer afhankelijk bent van de eigenschappen van je verbinding – zelfs met een satelliet verbinding zoals gebruikt door bijvoorbeeld marineschepen of de baggerschepen van van Oord worden goede resultaten geboekt!
Mij lijkt dat de inzet van een lokaal distributiepunt in de vorm van een SAN vereist dat je eerst alle content van dat distributiepunt bijwerkt. Pas daarna kan een gebruiker aan de slag met zijn applicaties en diens data. Tis te zeggen – ik heb geen weet van SAN’s die functioneel vergelijkbaar zijn.
@Will
Denk dat jij een kandidaat voor de Turing award bent als jij kunt voorspellen wanneer je een beroep moet doen op de back-up.
Dat je met deduplicatie, Wide Area File Services (WAFS), Common Internet File System (CIFS) proxy, HTTPS Proxy, media multicasting, web caching, bandbreedte management en andere L7 opties tot WAN acceleratie van het dagelijkse (gebruikers)verkeer tussen bij- en hoofdkantoor komt geloof ik. Sterker nog, Riverbed lijkt hier de beste te zijn:
http://www.networkworld.com/article/2287792/wan-optimization/126633-Top-tools-for-WAN-optimization.html
Nu lijk je het hier echter meer te hebben over DC2DC verkeer, and that’s another ballgame…..
Laten we zeggen dat ik een déjà vu had toen ik het verhaal las omdat er nog weleens te licht gedacht wordt over de back-up, als je over RTO/RPO begint dan moet je het ontwerp hiervan omgekeerd doen want het is vaak een ‘alles-of-niets’ oplossing als je alleen maar oog hebt voor het back-up window. Maar goed, dat is ook een vorm van data reductie;-)
Nou inderdaad – het ging dus *niet* over DC-2-DC verkeer. Er zijn weliswaar accelerators die voor dat doel gemaakt zijn. Maar dat is niet waar dit artikel over gaat.
Waar het dan wel over gaat? Over een aanpak om tijd te winnen bij het maken *en* het terugzetten van een backup. Alleen dan toegespitst op een DC aan de ene kant en bijkantoren met een eigen computerruimte en een handjevol servers aan de andere kant.
Het winnen van tijd bij het terugzetten van een backup gebeurd door een educated guess (voorspelling?) te doen naar de data die op enig moment nodig is om de zaak snel op te kunnen starten en die alvast naar de andere kant te sturen.
Dat lijkt me wat anders dan voorspellen wanneer een backup nodig is. Als ik inderdaad dergelijke voorspellende gaves had, dan was ik vrijwel zeker met andere dingen bezig dan het schrijven van artikelen en reacties… naar verwachting nog steeds geen dingen die helpen bij het scoren van een Turing award… maar of ik dat erg zou hebben gevonden… 🙂
Kijk ook eens naar hoe nieuwe technologien dit probleem aanpakken.
SimpliVity (www.simplivity.com) heeft technologie ontwikkelt waardoor alle data efficient worden opgeslagen door gebruik van inline deduplicatie en compressie. Dit sorgt er ook voor dat er bijvoorbeeld geen WAN optimalisatie technieken nodig zijn binnen een SimpliVity omgeving.
@Ewout,
“Hetzelfde geldt voor de incremental, differental en synthetic back-up technieken welke allemaal prachtig zijn om het back-up window te verkleinen maar weinig helpen bij herstel”
Deduplicatie werkt zeer zeker ook snel voor herstel. Een redelijk recentelijke “snap” van de data icm deduplicatie verkort het herstel enorm.