

Rest en Linked Data zijn dé best practices voor het publiceren en ontsluiten van open data. Wat hebben deze principes, standaarden en technieken wat andere niet hebben?
In een vorig artikel beschreef ik vier typen gegevensuitwisseling in onze verappte hyperconnectieve wereld. Bij hergebruik van open data vindt gegevensuitwisseling plaats op grotere schaal en met minder ruimte voor wederzijdse afstemming dan vroeger. Dat stelt hogere eisen aan schaalbaarheid en flexibiliteit van de toegepaste koppelingen dan wat de klassieke soa-paradigma’s alleen ons bieden.
Eisen
Bij hergebruik van open data ken je als data producent je afnemers niet (lage organisatorische cohesie). Afnemers gebruiken je gegevens voor doorgaans onvermoede doelen (lage proces cohesie). Toch wil je ook hier structuur, betekenis en levenscyclus van je data kunnen aanpassen en uitbreiden zonder dat daardoor het hergebruik spaak loopt. Als data-consument wil je een zo goed mogelijk rendement van je data client en zoveel mogelijk (vergelijkbare) datasets kunnen ontsluiten met dezelfde client. Zowel technisch, procesmatig als semantisch graag. En uiteraard zonder opgedrongen release ritme. Rest principes en Linked Data technieken bieden de hiervoor benodigde los gekoppelde interoperabiliteit.
Met Rest kun je schaalbare en flexibele api’s realiseren door het gebruik van standaard http-functies en het Hateoas-principe. Linked Data technieken faciliteren naast api’s ook filetransfer en embedded publicatie en ontsluiting. Met de RDF-standaard en door publicatie van vocabulaires wordt op een flexibele manier syntactische en semantische compatibiliteit geborgd.
Daarnaast gebruiken zowel Rest en Linked Data uri’s als unieke identificatiecodes voor personen, producten, aanvragen, dossiers et cetera. Via het globale DNS-mechanisme is zo op een doeltreffende manier het eenduidige wereldwijde auteursrecht belegd voor het toekennen van deze unieke codes (namelijk bij de eigenaar van het betreffende internetdomein).
Rest
Het centrale concept in Restis een resource, een virtueel of fysiek bestand op een server met informatie over één of meerdere personen, producten, aanvragen, dossiers et cetera. Afschriften van deze informatie (zogenaamde representations) worden uitgewisseld tussen server en client. Dit gebeurt altijd met standaard http-aanvragen zoals ‘get’ en ‘post’ en dus niet via customized webservices met telkens andere functionaliteit. Nuttig voor de schaalbaarheid.
Een representation bevat alle informatie die een client nodig heeft om het (client)applicatieproces naar een volgende status te sturen. Dit doet de client door één van de hyperlinks (uri’s) te kiezen die in een representatie zitten en die te volgen (dat wil zeggen de volgende representatie aan te vragen). De client hoeft dus niet a-priori op de hoogte te zijn van de mogelijke statussen van de resources op de server. Dit principe heet Hypertext As The Engine Of Application State (Hateoas).
Dat, samen met het stateless karakter van Rest-interacties (de server houdt niet bij wat de client doet), maakt Rest-processen uitermate loosely coupled. De server kan levenscycli van resources aanpassen zonder dat de client daar last van heeft, en wijzigingen in het clientproces zijn transparant voor de server. Hoge mate van flexibiliteit dus.
Met een Rest-aanpak kun je niet alleen gegevens opvragen, maar ook wegschrijven. Ook dat gebeurt op een flexibele manier. Je doet daarvoor geen update maar een ‘post’ = ‘op de bus doen’. Vervolgens kan een onafhankelijk serverproces de brievenbus legen en verwerken.
Als je op Rest gebaseerde interacties (‘Restful’ webservices of api’s) vergelijkt met soap, dan hoef je bij Rest dus geen namen, functionaliteiten en parameters te kennen. Bovendien zorgen de Rest-principes voor minimale pre- en postcondities. Het enige wat je moet weten is wat de resources zijn en welke uri’s ernaar verwijzen.
Vergelijk webservices met webpagina’s. En zie de aanroep van zo’n webservice vanuit de ontsluitende applicatie als een webbrowser. Met soap heb je dan voor elke webpagina een andere browser nodig. Met Rest bouw je webpagina’s die allemaal met dezelfde browser ontsloten kunnen worden.
Restful webservices en api’s zijn simpel zelf te bouwen. Maar er zijn ook speciale software development kits voor (SDK) zoals OData van Microsoft of GData van Google.
Linked Data
In tegenstelling tot Rest richt Linked Data zich niet zozeer op de interactie tussen producent en afnemer van open data, maar meer op de uitgewisselde datastructuren. Linked Data gaat daarbij meer in detail dan Rest: niet alleen objecten (resources) krijgen een uri (dus personen, producten, aanvragen, dossiers et cetera), maar ook de beschrijving van eigenschappen van objecten.
De RDF-standaard beschrijft het meta datamodel van Linked Data en hoe dat werkt met objecten, eigenschappen, relaties daartussen en uri’s. Het begrip triple staat daarin centraal: een elementaire datastructuur opgebouwd uit een object, een eigenschap en de waarde van die eigenschap. Zoals “deze blog”/”heeft als onderwerp”/”open data”. Op deze manier zijn data en metadata op een flexibele manier gekoppeld. Je kunt zo alle datastructuren als een verzameling triples weergeven.
Triples kun je makkelijk opslaan in speciaal daarvoor ontworpen databases (triple stores). Het is voor de uitwisseling van RDF-data verder niet van belang of de gegevens uit een triple store komen of uit een relationele database (of ergens anders vandaan).
Wel van belang is dat triples in platte tekst omgezet moeten worden om ze in bestanden of berichten uit te kunnen wisselen. Dat kan met één van de RDF ‘serialization’-standaarden (N3, turtle, JSON-LD, RDF/XML, …). Dit soort serialisaties wordt overigens ook gebruikt bij Rest-representaties.
Ook annotaties die met μF, Microdata of RDFa in (X)html als ‘embedded’-data op een webpagina zijn opgenomen kun je zien als Linked Data. Met GRDDL kun je die embedded data van de pagina halen en omzetten naar een ‘nette’-RDF serialisatie.
Behalve via een webpagina of een bestand kun je Linked Data ook uitwisselen via een api. Een van de belangrijkste Linked Data standaarden is de SPARQL api. Dit is een RDF-zoektaal die op SQL lijkt.
Het coole van SPARQL is dat je gemakkelijk meerdere datasets kunt integreren. Je hoeft technisch maar met één SPARQL server (endpoint) te koppelen om geïntegreerde queries te kunnen doen over alle SPARQL-datasets op het internet. Het nadeel is dat SPARQL voor app-bouwers niet heel makkelijk is om mee te werken.
Een heel andere api voor Linked Data is het Linked Data Platform van het W3C (LDP). Dit is een recente standaard waarmee je Linked Data op een Restful manier kunt opvragen en wegschrijven. Daardoor lijkt het overigens enigszins op OData en GData. Het verschil is dat het LDP geen SDK is, maar de specificatie van het gedrag van de standaard Restful Linked Data-Aapi Verder missen OData en GData de syntactische en semantische flexibiliteit van RDF. Ze ontsluiten alleen enkelvoudige ‘silo’-datasets. RDF is met zijn strakke gebruik van uri’s veel meer gericht op het linken en integreren van datasets.
Voor integratie van datasets is het – naast het kunnen linken – belangrijk om deze te kunnen repliceren en om de integriteit van links te bewaken. Hiervoor wordt nog gewerkt aan push notifications, een mechanisme om wijzigingen in open datasets proactief te melden bij afnemers.
Semantische interoperabiliteit
Door de ontleding van datastructuren in RDF-triples worden dus alle gegevensbestanden syntactisch compatibel. De (meta)informatie die je bij het vertrippelen van relationele structuren kwijt zou raken voeg je met de RDF Schema taal (RDFS) weer toe. Aan dezelfde verzameling triples, dus zelfbeschrijvend en nog steeds syntactisch compatibel.
Semantische compatibiliteit wordt geborgd door in de triples gebruik te maken van standaard vocabulair voor het beschrijven van de eigenschappen van objecten in een triple. Doordat een eigenschap in een triple ook een eigen uri heeft, kun je daarmee verwijzen naar gepubliceerde wereldwijde standaard vocabulaires zoals Dublin Core en FOAF. Maximaal eenduidig over meerdere datasets heen = semantisch interoperabel.
Daarnaast kunnen talen als SKOS en OWL een geheel aan relaties definiëren tussen de objecten van triples, inclusief beperkingen in het gebruik van eigenschappen en relaties. Dat noemen we een ontologie. Die talen worden daarom vaak niet vocabularies genoemd maar ontology languages. Ontologieën ondersteunen niet alleen het menselijk begrip van de betekenis ‘in’ een dataset, maar ze zijn ook de basis voor reasoners en ontology matching systems. De eerstgenoemde tools kunnen logische conclusies trekken uit een dataset; de tweede zoeken overeenkomsten tussen ontologieën, en leggen zo verbanden tussen betekenissen van datasets.
Een belangrijk kenmerk van het RDF-model is flexibiliteit. Je kunt inhoud, structuur of betekenis van een triple dataset altijd wijzigen zonder dat de publicatie of ontsluiting van die dataset moet worden aangepast. Andersom geldt dat je geen structurele conclusies kunt trekken uit het niet aanwezig zijn van objecten, kenmerken of relaties in een dataset. Die zouden best elders in een (nog toe te voegen of te koppelen) dataset kunnen zitten. Dit principe noemen we de Open World Assumption (OWA).
Toekomst
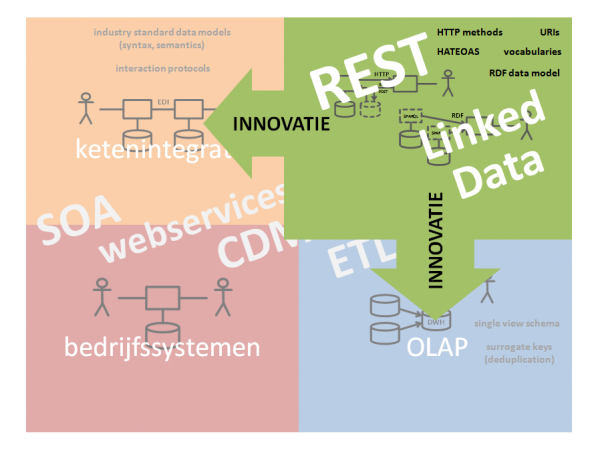
De voordelen van deze best practices op het gebied van schaalbaarheid en flexibiliteit zullen ook buiten het open data domein nuttig gebruikt gaan worden. Vervang de interoperabiliteitsmechanismen ‘single view schema’ door ‘vocabularies’ + ‘RDF datamodel’ en ‘surrogate keys’ door úri’s’ en je ziet wat Linked Data voor olap kan betekenen. Hetzelfde geldt voor ketenintegratie. ‘Vocabularies’ + ‘RDF datamodel’ kan prima ‘industry standard data models’ vervangen. En ‘http methods’ + ‘hateoas’ is het betere alternatief voor traditionele ‘interaction protocols’.
Oude wijn in nieuwe zakken? Jazeker. Maar dan zakken die een stuk simpeler, schaalbaarder en flexibeler zijn. En op de langere termijn dus goedkoper.








