

Naast dat information discovery-producten, zoals Attivia en Oracle Endeca Information Discovery, een goede aanvulling op bestaande business intelligence (bi)- en datawarehouse (dw)-omgevingen vormen, zijn ze uitermate geschikt om snel een 'gevoel' voor nieuwe gestructureerde en ongestructureerde bronnen te krijgen. En dat gevoel is nu juist vaak wat ontbreekt om een succesvolle start met big data te kunnen maken.
Veel organisaties beschikken voor hun management informatievoorziening over een datawarehouse- en business intelligence-omgeving. In deze omgeving worden batchgewijs gegevens uit verschillende transactionele systemen geladen en verwerkt tot rapportages en analyses. Om in de informatiebehoeften te kunnen voorzien werkt men binnen deze omgeving vaak met een top-down aanpak waarbij eerst wordt vastgesteld welke (nieuwe) vragen er beantwoord moeten worden. Vervolgens richt men de datalogistiek en rapportages hierop in. Het goed inrichten van de datalogistiek is een activiteit die je niet moet onderschatten. Het structureren, combineren en verwerken van de gegevens uit de verschillende systemen tot een consistente set aan historische en actuele informatie vergt de nodige inspanning.
Big data
Waar bij het datawarehouse de datalogistiek wordt ingericht om in een vooraf bepaalde informatiebehoefte te kunnen voorzien, is het uitgangspunt van big data nu juist om de data zoveel mogelijk ongemoeid te laten en de vragen te vertalen naar programmatuur die de data bevraagt. En waar het bij een datawarehouse alleen om gestructureerde data gaat, gaat het bij big data ook om ongestructureerde en semigestructureerde gegevens, die niet netjes in rijen of kolommen van een database passen. Het gaat dan om bijvoorbeeld tekstdocumenten, social media berichten, maar ook zelfs om video en audio.
Hoewel de belofte van big data groot is, zijn er nog maar weinig organisaties die al de nodige stappen op dit gebied maken. Dat komt mede doordat het vaak lastig is om vooraf een goede business case op te stellen. Je weet immers van tevoren niet welke nieuwe inzichten al deze data je gaat opleveren en welke nieuwe toepassingen je hiermee kunt realiseren. Het is dus van belang om eerst wat meer gevoel voor deze data te krijgen.
Information discovery
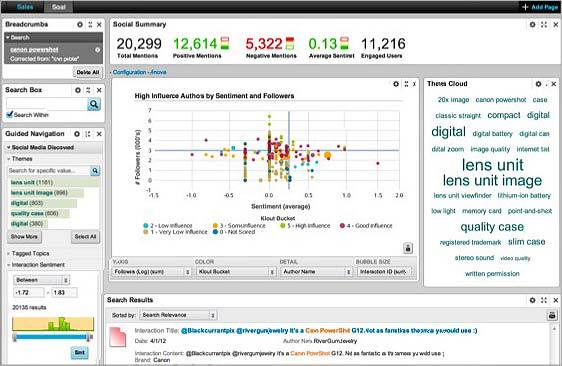
Information discovery-producten zoals Attivio en Oracle Endeca Information Discovery faciliteren het eenvoudig combineren en exploreren van gestructureerde en ongestructureerde data zonder dat er vooraf een (database) schema voor gedefinieerd hoeft te worden. Velden kunnen iedere lengte hebben en kunnen allerlei datatypen bevatten. Hierdoor bieden ze een grote flexibiliteit en snelheid van ontwikkelen. Nieuwe databronnen kunnen eenvoudig worden toegevoegd zonder dat daarvoor een schema hoeft te worden aangepast. Deze nieuwe bronnen worden door middel van gezamenlijke kollommen en/ of whitelists (flexibele vertaaltabellen) automatisch gerelateerd aan de data die al geladen is.
Deze informatie discovery-producten bieden visualisatie en dashboarding-functionaliteit en faciliteren het navigeren over gerelateerde items binnen gestructureerde en ongestructureerde gegevens. Daarnaast bieden ze uitgebreide zoekfunctionaliteiten. Bij het laden van de gegevens creëren ze een key-value achtige index, waarmee ze alles indexeren en die het doorzoeken van alle gegevens razendsnel maakt. Ze hebben een google-achtige searchinterface die zelf met suggesties komt wanneer een gebruiker een spelfout maakt, of wanneer erop lijkende woorden veel meer resultaten geven.
Information discovery voor bi en big data
Door hun intuïtieve interface en flexibele architectuur zijn deze information discovery-producten uitermate geschikt om nieuwe, gestructureerde maar ook ongestructureerde databronnen te verkennen. Ze vormen daarmee niet alleen een goede aanvulling op een bestaande business intelligence- en datawarehouse-omgeving, maar kunnen ook ingezet worden om de eerste stappen richting big data succesvol te doorlopen. Daarvoor is immers een goed gevoel voor de data van essentieel belang.









Ik krijg een beetje een sik van weer een…..
Leg de mensen nu eerst eens fatsoenlijk uit wat Big Data is. Wat je daarmee kunt. De technieken zijn beslist niet weggelegd voor elke MKB-er bijvoorbeeld omdat de investering soms aanzienlijke vormen kan aannemen op verschillend vlak.
Denk hier eens even aan bandbreedte die je mag gaan betalen en natuurlijk opslag. Vervolgens, een ondergeschoven kindje die ik telkens weer ontdek in verschillende gesprekken die ik met die en gene over Big Data had, ‘De Vluchtigheid van Big Data’.
Eenvoudig voorbeeld, twitter, facebook, Whats app, Telegram, e.d. genereren flink wat data waar je domweg in 60% van de gevallen geen moer aan hebt.
Veel mensen zorgen ervoor dat hun koekies weg worden gegooid met als gevolg dat je een enorme vervuiling krijgt van die ‘Big Data’. Hoe groot is die vervuiling, hoe groot is de impact op de cijfermatige benadering van die big data? Niemand die het me kan vertellen.
Toch wel een interessant gegeven te weten als ik iets met big data wil gaan doen. Waarom zou ik namelijk moeten betalen voor vuile was? je kunt uiteindelijk overal een punt aan zuigen nietwaar?