

Stel, de provider waar je al jouw bedrijfsapplicaties hebt ondergebracht ondervindt een heftige storing. Het is inmiddels dag zes van de storing en de bedrijfsapplicaties zijn nog steeds offline. De provider is telefonisch en per e-mail volstrekt onbereikbaar en communiceert geen oplostermijn. Als dat het moment is waarop jij je realiseert dat je een plan had moeten hebben voor dit soort scenario’s, ben je te laat. Er zit niets anders op dan te wachten tot de provider de storing weer onder controle heeft en de dienstverlening wordt hervat.
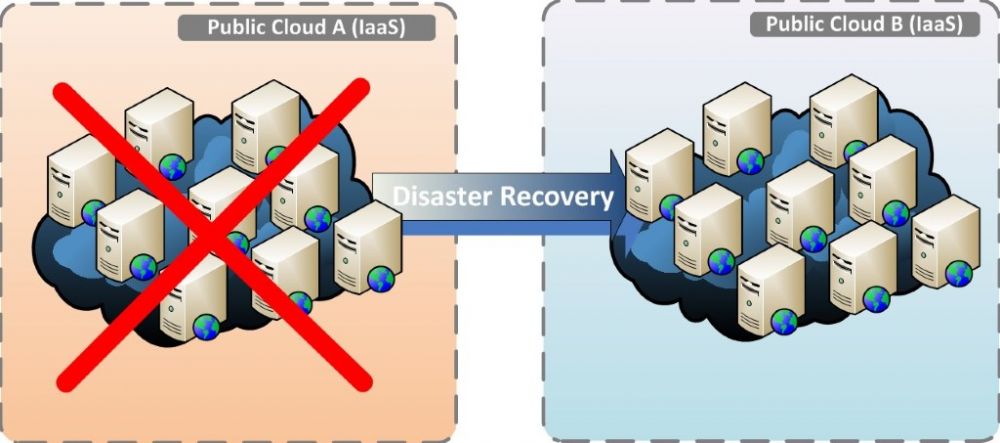
De afgelopen weken heeft een dergelijk situatie zich voorgedaan bij een provider in Nederland. Ik heb diverse klanten van deze provider aan de telefoon gehad, met de paniek doorklinkend in hun stem. Voor deze klanten kon ik alleen iets betekenen als ze zelf over een kopie van de data en de applicaties beschikten, voor de meesten zat er niets anders op dan te wachten en ervan te leren. In dit artikel lees je welke mogelijkheden je hebt als afnemer van IaaS en waar jouw beperkingen liggen.
Er zijn diverse methodieken beschikbaar om de continuïteit van de applicaties te waarborgen in het geval van een storing in de infrastructuur van de provider. Het nadeel van de meeste van deze oplossingen is dat ze de medewerking van de provider vereisen voor de inrichting, het beheer en onderhoud, maar bovenal voor de daadwerkelijke uitwijk. En dat is nou precies het punt: de provider is onbereikbaar.
Private cloud
Idealiter kun je als klant zelf beslissen over de inzet van een disaster recovery (dr)-oplossing en kun je de daadwerkelijke uitwijk ook zelf initiëren. Bij het gebruik van een private cloud (IaaS) zijn er diverse mogelijkheden om een betrouwbare dr-oplossing te implementeren. Denk hierbij bijvoorbeeld aan:
- Stretched virtualisatie clusters (EMC Vplex / NetApp Metro Clusters).
- Storage gebaseerde replicatie in combinatie met geautomatiseerdedr- tooling (EMC Recoverpoint, HP Lefthand in combinatie met VMware vSphere Site Recovery Manager).
- Replicatie op virtualisatie niveau (Veeam Backup & Replication/Zerto Virtual Replication/Novell Platespin Migrate).
Public cloud
Bij public cloud (IaaS), waar er meerdere klanten op dezelfde fysieke infrastructuur draaien, zijn de mogelijkheden aanzienlijk beperkter en bovendien lastiger te realiseren. De professionelere providers hebben een dr-oplossing in het standaard product portfolio (wees bedacht op goed bedoelde specials). Zijn deze er niet, dan ben je aangewezen op de oplossingen die binnen het controledomein van jou als klant liggen. Meestal behelst dit alles vanaf de virtuele laag tot aan de applicatie. Replicatie op virtualisatie niveau is dan een mogelijkheid. Deze oplossingen zijn echter (op dit moment) nog onvolwassen als het gaat om public cloud (IaaS). Het resultaat is dus dat de disaster recovery in zo’n geval ingeregeld moet worden vanaf de operating system- en applicatie-lagen. Mogelijkheden zijn bijvoorbeeld het inrichten van replicatie op dataniveau en het clusteren van applicaties over meerdere cloud-providers. Dit vereist complexere ontwerpen voor data-synchronisatie en applicatie-clustering.
Wat me bevreemd is dat de meeste gebruikers van (public en private) cloud IaaS diensten ten onrechte denken dat de provider zorg draagt voor dr-diensten terwijl toch duidelijk uit het sla blijkt dat dit niet het geval is. De inrichting van dr is klant-specifiek en vereist een gedegen kennis van de infrastructuur van de klant. Providers die hierin excelleren hebben bij de inrichting van hun infrastructuur de juiste keuzes gemaakt en daarmee het fundament gelegd voor een goede recovery.
Mijn advies: leer van de situaties zoals die zich recent hebben voorgedaan en test of jouw huidige dr-plan voldoet aan de eisen van vandaag. Het is daarbij prima om te vertrouwen op de dr van je provider, maar test dan tenminste wel minimaal elke zes maanden. Besteed dan speciaal aandacht aan recente wijzigingen, gemaakt aan de applicaties en infrastructuur. Een veel gemaakte fout is dat wijzigingen aan de infrastructuur niet doorwerken in de dr-oplossing, met catastrofale gevolgen bij een werkelijke uitwijk.
Zelf volledig in control zijn? Richt dan een dr-oplossing in die binnen je controledomein ligt. De continuïteit van de onderneming ligt op de weegschaal. Handel snel maar vooral zorgvuldig.









@Reza; flauw, dan zijn het holle kreten als je geen vendors kan noemen, of het zijn niche spelers blijkbaar, jammer dat er slechts abstracte ervaringen door je worden benoemd…daar was ik al bang voor, dat t nooit echt concreet wordt. Ik vind ook weleens een website niet zo goed, maar dat maakt niet het hele internet waardeloos!
Lennart,
Als ik tegen mijn jongste kind zeg dat ze niet krijgt wat ze vraagt (om een bepaalde reden) dan probeert ze mij met alle middelen te manipuleren om haar zin te krijgen. Herkenbaar dit gedrag?
Lees aub nog een keer mijn reactie. Dan zou je moeten weten dat ik gebonden ben aan bepaalde bedrijfspolicies en afspraken.
Lennart,
Mooi gevonden dat ‘Edge case’ en heel toepasselijk bij het onderwerp, vaak is een spiegel contractueel wel afgesproken maar blijkt deze in de praktijk gebroken. Zo bleek eens bij organisatie (we noemen geen namen) de service wel keurig automatisch overgegaan naar de uitwijk maar was dit niet geconstateerd. En omdat daardoor de conditie die hiervoor zorgde ook niet opgelost werd bleek er effectief dus geen uitwijk meer te zijn, al weken niet meer.
Dat deze zaken minder breed in het nieuws komen is meestal het gevolg van mister ‘Corner case’ waardoor het niet makkelijk is om van vendor te wisselen. Kijkend naar de cloud zie ik telkens wel definitie wijzigingen maar nog niet echt de verbeteringen in techniek die zorgen dat alle beloften ook ingelost kunnen worden. Ik kan het mis hebben maar gaat het er in de wetenschap niet om de verhouding van theorie en werkelijkheid te toetsen?
Ligt het aan mij of wordt af en toe vergeten dat “cloud” ook een berg hardware betekent?
Hardware die kapot kan gaan en ondanks clusters, virtualisatie, replicatie, mirrorring etc. etc. toch net dat ene komponentje die wolk als een ballon laat klappen.
Uit mijn ervaringen en die van kollega’s weet ik dat niemand kon verwachten dat de bliksem-inslag de kabelboom in de kabelschacht tot een perfect brandende schoorsteen maakte, en ach, zonder kabels weinig ICT!
Het begrip “restrisiko” is ook bij cloud-oplossingen van toepassing.
Je kunt je juridisch nog zo goed indekken, wanneer kalamiteiten gebeuren helpt dat niets.
Een uitwijk voor een uitwijk vind ik wat overdreven, een termijn voor herstel is de betere optie zodat de oorspronkelijke uitwijk weer zijn funktie krijgt.
Bij een groeiende komplexiteit in het algemeen, zullen dit soort systemen, cloud of niet, af en toe plat gaan, dat was zo, is zo en zal wel zo blijven om het even of IAAS, SAAS of wat dan ook.
Geachte collega Experts van Computable,
Sinds het publiceren van het artikel op vrijdagavond, en nu zondag avond, is er een heuse discussie ontstaan die veel verder reikt dan de scope van het initiële artikel.
Zoals jullie terecht concludeerden en de titel deed vermoeden: mijn stuk was ge-ent op mijn ervaringen met het IaaS portfolio van cloud providers. SaaS is een geheel ander spel waarbij hele andere dimensies een rol spelen. Ik vind het vervelend te moeten melden, maar mijn ervaring is dat de meeste SaaS diensten (behoudens die van hele grote corporaties) helemaal niet ingesteld zijn op het mitigeren van een calamiteit, laat staan dat ze beschikken over meerdere datacenters waar active/active dienstverlening vanuit geboden wordt. De meeste SaaS providers die ik begeleid gebruiken op hun beurt gewoon weer IaaS (of PaaS) providers om hun diensten bij onder te brengen. Hierbij moet ik wel vermelden dat ik voornamelijk in Nederland actief ben dus hoofdzakelijk over Nederlandse SaaS providers spreek. SaaS leveranciers staan onder enorme druk om op prijs/functionaliteit te concurreren en een goed DR-plan past simpelweg niet in dat plaatje.
Als klant van SaaS doe je er dus goed aan om zelf op regelmatige basis een backup te vervaardigen van de data die je bij de SaaS provider hebt ondergebracht. Denk er daarbij wel om dat je dit doet in een format wat zo veel mogelijk applicatie onafhankelijk is. Bij een calamiteit bij de SaaS provider is de applicatie natuurlijk niet meer beschikbaar wat het teruglezen van de backup lastig maakt.
Om verder in te zoomen op het probleem wat veel IaaS klanten onbewust lopen; dit is een probleem wat voornamelijk ingegeven wordt door het gebrek aan vaardigheden om een juist en volledig SLA te onderhandelen en om de maatregelen die de IaaS provider heeft genomen te beoordelen. Helaas is het zo dat een afgegeven garantie voor beschikbaarheid (negenennegentig komma veel) gebaseerd op operaties onder normale omstandigheden. Du moment dat er zich een calamiteit van enige omvang voordoet kan de IaaS provider zich conform overeenkomst (niet SLA!) beroepen op het Force Majeur artikel. De afgegeven beschikbaarheidsgarantie komt in dat geval te vervallen, de verzekeraar van de IaaS leverancier gaat hopelijk tot uitkeren over en de klant heeft recht op een vergoeding van de (directe) schade tot maximaal het bedrag van de maandfactuur. Uiteindelijk zal de dienstverlening hersteld worden, maar niet voordat er serieuze schade is geleden.
Als afnemer van IaaS dien je er dus van bewust te zijn dat een SLA met een Force Majeur clausule geen dekking biedt in het geval van een calamiteit. Er zijn diverse mogelijkheden om daar mee om te gaan, maar de strekking van mijn artikel was juist: regel het op zo’n manier in dat je als afnemer van de IaaS dienst zelfstandig(!) de DR oplossing kunt initiëren. Dit kan door middel van een bij de IaaS provider afgenomen DR-dienst of een zelfstandig ingerichte DR-oplossing bij een andere provider.
Ik hoop hiermee wat aanvullende informatie verschaft te hebben over de achtergrond van het artikel.
Met vriendelijke groeten,
Bart M. Veldhuis
@Reza; ja dat hebben we allemaal, maar je spreekt over een grote SaaS leverancier die je niet kan bellen en geen maatwerk toestaat en waar je de naam niet van kan noemen, dat kan nooit een serieuze SaaS club zijn IMHO, want dan zou ik em kennen, en alle serieuze SaaS leveranciers hebben grote support-afdelingen, die je gerust mag bellen…
Maar ik laat het erbij, het voegt aan dit artikel niks toe,
Bart,
Het heeft even geduurd maar leuk dat je op je artikel terug bent gekomen.
Ik denk dat deze reactie een wake up call moet zijn voor mensen die door cloud betoverd zijn. “Denk in oplossingen, denk in mogelijkheden denk in….” zijn leuke praatjes die niet altijd realistisch zijn.
Korte reactie op je toelichting, zoals in de reacties boven besproken is, het maken van een back-up lost je probleem niet op als je moet uitwijken. Een uitwijkscenario behoeft nog meer dan alleen een restore van data.
Voor de rest zie ik je reactie in lijn met reacties hierboven van reageerders die nuchter met beide benen op de grond staan.
@Bart
Dank voor je aanvulling en misschien dat reacties verder reiken dan je intentie was maar volgens mij zitten er toch interessante lijntjes in het zand bij.
Je zegt dat wijzigingen in infrastructuur impact hebben op DR plannen, correct opgemerkt maar hoe zit het met configuration management?
Je zegt dat de afnemers van IaaS in hosted public cloud oplossing zelf hun DR moeten initieren maar hoe zit het dan met event management?
De twee bovenstaande maar niet limitatieve punten komen uit de ervaringen met data center migraties, in de prakijk vaak gewoon een DR test. En juist dan blijken iedere keer weer verrassingen naar boven te komen omdat er wat achterstallige administratie is. Betreffende event management is dat trwouens vaak een intern gericht proces waardoor dus uiteindelijk een incident de trigger is voor uitwijk.
Natuurlijk maken software defined oplossingen de replicatie en migratie eenvoudiger maar uiteindelijk gaat het gewoon om een proces, de techniek is maar een onderdeel hiervan. Oja, als je applicatie hiervoor niet geschikt is dan blijft het uiteindelijk gewoon meer geluk dan wijsheid. Dat sommige SaaS oplossingen gewoon een database met prefix zijn herken ik ook wel – het is maar net vanaf welke kant je naar oplossingen kijkt;-)
@Reza
Ik ben het niet met je eens, cloud computing biedt mogelijkheden om de DR kosteneffectief te verbeteren. Juist door in oplossingen te denken met een kennis van de techniek. Zo kun je heel goed uitwijken naar de cloud, niet alleen als herstel van je business maar ook om tijdelijke pieken op te vangen of een tijdelijk service te hosten.
Bart geeft een aantal mogelijkheden om middels de storagelaag de portabiliteit van je workload te vergroten, ik heb hier alleen nog wat vragen over de beheer(s)laag. En dat is geen ‘Edge Case’ maar ‘Boundary Edge’ want wat ik ontzettend mis is de opkomende ontwikkeling van Community cloud. Deze samenwerking adresseert naar mijn opinie namelijk een heleboel van de openstaande punten die Bart nu mogelijk bij één afnemer legt.
Lennart of Henri nog aanvullingen?
Hier hebben onze Oosterburen het perfecte woord voor uitgevonden.
Schadenfreude.
Als je als professional nog in dit soort vallen trapt dan mag je je serieus afvragen of je die titel nog langer verdiend.
Ewout,
Waar ben je het niet met mij eens? Ik heb het niet vastgelegd dat cloud computing als je DR oplossing per definitie duurder is. Dat hangt van je situatie en case af. Bijvoorbeeld twee gemeenten die samen gaan werken kunnen van elkaars locatie en middelen gebruik maken voor DR zaken. In dat geval zou cloud duurder zijn dan misschien wanneer je geen samenwerkingsverband hebt. Dit is iets wat er per geval bekeken moet worden.
P.s. leuk te zien dat je aan de kennis van andere mensen ook een plek geeft 🙂