

Stel, de provider waar je al jouw bedrijfsapplicaties hebt ondergebracht ondervindt een heftige storing. Het is inmiddels dag zes van de storing en de bedrijfsapplicaties zijn nog steeds offline. De provider is telefonisch en per e-mail volstrekt onbereikbaar en communiceert geen oplostermijn. Als dat het moment is waarop jij je realiseert dat je een plan had moeten hebben voor dit soort scenario’s, ben je te laat. Er zit niets anders op dan te wachten tot de provider de storing weer onder controle heeft en de dienstverlening wordt hervat.
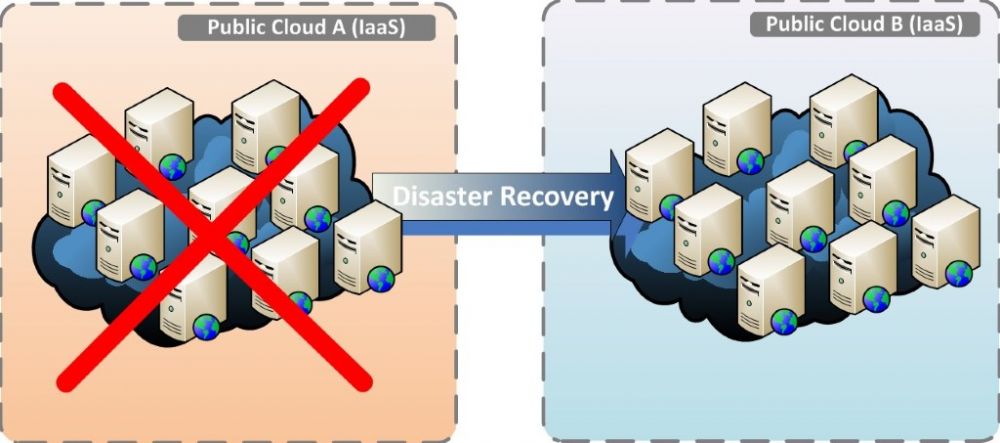
De afgelopen weken heeft een dergelijk situatie zich voorgedaan bij een provider in Nederland. Ik heb diverse klanten van deze provider aan de telefoon gehad, met de paniek doorklinkend in hun stem. Voor deze klanten kon ik alleen iets betekenen als ze zelf over een kopie van de data en de applicaties beschikten, voor de meesten zat er niets anders op dan te wachten en ervan te leren. In dit artikel lees je welke mogelijkheden je hebt als afnemer van IaaS en waar jouw beperkingen liggen.
Er zijn diverse methodieken beschikbaar om de continuïteit van de applicaties te waarborgen in het geval van een storing in de infrastructuur van de provider. Het nadeel van de meeste van deze oplossingen is dat ze de medewerking van de provider vereisen voor de inrichting, het beheer en onderhoud, maar bovenal voor de daadwerkelijke uitwijk. En dat is nou precies het punt: de provider is onbereikbaar.
Private cloud
Idealiter kun je als klant zelf beslissen over de inzet van een disaster recovery (dr)-oplossing en kun je de daadwerkelijke uitwijk ook zelf initiëren. Bij het gebruik van een private cloud (IaaS) zijn er diverse mogelijkheden om een betrouwbare dr-oplossing te implementeren. Denk hierbij bijvoorbeeld aan:
- Stretched virtualisatie clusters (EMC Vplex / NetApp Metro Clusters).
- Storage gebaseerde replicatie in combinatie met geautomatiseerdedr- tooling (EMC Recoverpoint, HP Lefthand in combinatie met VMware vSphere Site Recovery Manager).
- Replicatie op virtualisatie niveau (Veeam Backup & Replication/Zerto Virtual Replication/Novell Platespin Migrate).
Public cloud
Bij public cloud (IaaS), waar er meerdere klanten op dezelfde fysieke infrastructuur draaien, zijn de mogelijkheden aanzienlijk beperkter en bovendien lastiger te realiseren. De professionelere providers hebben een dr-oplossing in het standaard product portfolio (wees bedacht op goed bedoelde specials). Zijn deze er niet, dan ben je aangewezen op de oplossingen die binnen het controledomein van jou als klant liggen. Meestal behelst dit alles vanaf de virtuele laag tot aan de applicatie. Replicatie op virtualisatie niveau is dan een mogelijkheid. Deze oplossingen zijn echter (op dit moment) nog onvolwassen als het gaat om public cloud (IaaS). Het resultaat is dus dat de disaster recovery in zo’n geval ingeregeld moet worden vanaf de operating system- en applicatie-lagen. Mogelijkheden zijn bijvoorbeeld het inrichten van replicatie op dataniveau en het clusteren van applicaties over meerdere cloud-providers. Dit vereist complexere ontwerpen voor data-synchronisatie en applicatie-clustering.
Wat me bevreemd is dat de meeste gebruikers van (public en private) cloud IaaS diensten ten onrechte denken dat de provider zorg draagt voor dr-diensten terwijl toch duidelijk uit het sla blijkt dat dit niet het geval is. De inrichting van dr is klant-specifiek en vereist een gedegen kennis van de infrastructuur van de klant. Providers die hierin excelleren hebben bij de inrichting van hun infrastructuur de juiste keuzes gemaakt en daarmee het fundament gelegd voor een goede recovery.
Mijn advies: leer van de situaties zoals die zich recent hebben voorgedaan en test of jouw huidige dr-plan voldoet aan de eisen van vandaag. Het is daarbij prima om te vertrouwen op de dr van je provider, maar test dan tenminste wel minimaal elke zes maanden. Besteed dan speciaal aandacht aan recente wijzigingen, gemaakt aan de applicaties en infrastructuur. Een veel gemaakte fout is dat wijzigingen aan de infrastructuur niet doorwerken in de dr-oplossing, met catastrofale gevolgen bij een werkelijke uitwijk.
Zelf volledig in control zijn? Richt dan een dr-oplossing in die binnen je controledomein ligt. De continuïteit van de onderneming ligt op de weegschaal. Handel snel maar vooral zorgvuldig.









Dank @NumoQuest & @Henri.
@Henri:
A) Ik zie weer enorme verschil tussen hoe jij naar een ict-verschijnsel zoals BC/DR kijkt en hoe ik (of Ewout) het doe.
Heb je weleens met BC/DR van organisaties zoals ING te maken gehad? Zo ja dan ga je niet denken dat je met back-up / restore van data een BC/DR plan hebt of eens in dichtbij in de buurt komt.
B) je hebt verschillende scenario`s bij uitwijk zoals uitwijk van 1 dienst ( bijvoorbeeld mail of telefonie etc), uitwijk van een deel van je diensten en uitwijk van totale diensten/platform. Bij 1e en 2e vorm heb je te maken met verwevenheid van verschillende componenten, applicaties en diensten. Leuk dat je een mailbox export/import doet maar je hebt de betreffende dienst nog niet helemaal goed in elkaar gezet.
Bovendien je kunt sommige delen van een dienst bij andere dienst niet aanbieden. Denk aan PublicFolder van O365 die je in Google maildienst wilt inpassen! Heb je dat weleens geprobeerd?
Over PublicFolder O365 gesproken, heb je weleens geprobeerd de data van interne Exchange naar O365 te kopiëren? Zo ja, is het je iets opgevallen?
Je mag alles wat ik zeg onzin vinden maar ik baseer mijn reactie op zaken die ik meegemaakt heb.
B)Een klant maakte gebruik van een SaaS oplossing. Ze wilden een andere SaaS oplossing aanschaffen die met deze op verschillende niveaus moest kunnen communiceren. Sommige interface-delen van de nieuwe applicatie dienen voor sommige AD gebruikers onzichtbaar of grijs te zijn. Sommige functionaliteiten moesten of onzichtbaar worden of Only View of All-in rechten krijgen gebaseerd op 1) je AD groep 2) je locatie [ vesteging A, vesteging B, of thuis]
Gebaseerd op deze indicators en nog wat andere zaken (geen lange verhaal maken) moest er kunnen bepaald worden of een gebruiker bijvoorbeeld iets mag printen of exporteren of niet (op vestiging A en B mag en thuis niet)
Kortom een maatwerk voor een financiële instelling. na het opstellen van PvE zijn we snel erachter gekomen dat de betreffende SaaS oplossing niet de benodigde flexibiliteit kon aanbieden en de leverancier was ook niet in staat om daar maatwerk van te maken.
Heb ik nu antwoord op je 3e punt?
@Lennart
A) Als jij veel aannames hier ziet, kom jij maar dan met namen, feiten, referenties etc. Je vertel ook hier eea zonder duidelijke referenties.
Over aannames gesproken, wie zegt dat ik in onderwijs en zorg actief ben?
B) Als jij ook het exporteren van een database bij een Saas-leverancier als oplossing ziet voor DR/BC, dan adviseer ik je om een uitwijktest gebaseerd op deze oplossing uit te voeren.
Bovendien, een Saas-leverancier bepaalt zelf van welke soort database (bijvoorbeeld een exotische opensource) en ook indeling binnen de database gebruik gaat worden gemaakt. Dit betekent niet dat de geëxporteerde data altijd 1 op 1 bij een andere leverancier bruikbaar is.
C) Zoals je weet (!) een SLA beschrijft niet alleen de up-time maar ook nog veel andere zaken zoals reactietijden, oplostijden, escalatiezaken, kwaliteiten (snelheid, bruikbaarheid, etc)en nog andere componenten die de basis vormen voor de afspraken rondom de dienstverlening.
” SLA`s sterven ook uit in de SaaS / Cloud wereld, want de systemen zijn altijd up”
Ai, ai, ai, je schiet hiermee in je eigen voet. Zeer merkwaardig dat je in je uitspraak een SLA alleen aan de uptime koppelt.
Ben benieuwd hoe je me gaat helpen (je reactie van 10:38). Ja graag!
Het artikel is een schot in de roos. De problemen met IAAS zijn veel ICTers nog niet duidelijk laat staan de “managers” die de kontrakten tekenen.
Voorbeelden als Google Apps vindt ik niet zo passen bij het beschreven probleem, office-gebruik heeft een behoorlijke backup nodig en dat moet ook nog zonder internet kunnen werken (voor mij dus geen google . . ).
Reza heeft gelijk dat ING een andere dimensie is.
Het geschetst probleem met 6 dagen down is wel erg extreem, het toont hoe onrijp “cloud” is, technisch kan veel, maar rijpheid betekent ook een behoorlijke DR en juridisch behoorlijke kontrakten.
Kijkend naar het MKB zie ik nog veel problemen voor cloud-gebaseerd werken (IAAS). Waarschuwingen als dit artikel zijn nodig, met dank aan Lennart.
En Reza, 1000+, een echte Milestone, proficiat!
@Reza : kan je mij de partijen toesturen waar je alleen per mail mee kan communiceren, en welk maatwerk hebben we het dan over?
Reza,
Jij wilt ook geen lange verhalen schrijven waarmee je alle punten volledig afdekt, ik doe dat (deze keer) ook niet.
Ik zet nadrukkelijk bij dat het voorbeeld SaaS is, en ik ben niet in staat om voor een ING een DR strategie te ontwikkelen, aangezien we het niet over scope en grootte gehad hebben zou mijn reactie daar niet op afgerekend moeten worden.
Ook vermeld ik dat mijn voorbeeld niet perfect is noch compleet. Ieder bedrijf moet een risico analyse doen. Hoe groot is de kans dat een grote provider down gaat? En wat betekent dat dan? In mijn voorbeeld over Google ga ik er vanuit dat de kans dat er echt een disaster optreedt erg klein is, maar *als* het gebeurd is er in ieder geval een mogelijkheid om door te kunnen gaan. Die is niet compleet, die zal een hoop gepiel met zich meebrengen, maar je data heb je. Niemand heeft gezegd dat je disaster recovery super de luxe en compleet hoeft te zijn.
Dat er bedrijven zijn die in onwetendheid diensten af nemen en laks zijn in het maken van een risico analyse en een plan, tja “la gente esta muy loca”
Je reactie B heeft precies aan waar het manco zit. Je noemt een voorbeeld van een SaaS die geen maatwerk had en daarmee trek je die conclusie door naar alle SaaS. Overigens betekent het inderdaad wel dat als je gaat migreren je wellicht een organisatie verandering nodig hebt. Maar ik kan een hele berg maatwerk voorbeelden noemen. Net als mensen die ik kan bellen 24/7.
Het zwaartepunt van disaster recovery is dat je risico analyses doet en in ieder geval benul hebt hoe je in bepaalde scenario’s zou kunnen handelen. Perfect DR plannen bestaan niet en als ze zouden bestaan zijn ze onbetaalbaar.
En dat terugkerende SLA discussie. Natuurlijk wil je afspraken maken, maar een SLA voorkomt geen problemen en lost ze ook niet op. Het is iets wat er nu eenmaal bij hoort, maar het is verder niet zo heel interessant en vaak schijnveiligheid. Beschikbaarheid heeft zoveel gezichten, daar kun je boeken over schrijven…. Maar ook responsetijd is vaak een wassen neus. Je wilt gewoon een capabele leverancier met een goede mentaliteit en trackrecord aangevuld met “bewijs” (certificering en audit). De rest is koffie dik kijken.
Deze partijen bedoel ik, @Reza:
Ik denk dat je (in)direct doelt op grote SaaS spelers die misschien meer dc`s hebben. Maar als klant heb ik geen zin om altijd een dienst bij die grote leveranciers af te nemen. Dat komt o.a. doordat ik 1) hun SLA moet accepteren, 2) alleen via mail met hen mag communiceren, 3) geen maatwerk kan krijgen en nog meer.
Ik weet niet wat jij met maatwerk bedoelt, maar bij de SaaS oplossingen die ik ken kan je in hoge mate je eigen wensen uitbouwen (NetSuite, salesforce.com, Microsoft CRM Online, Workday); kortom, waar hebben we t over? Jouw drie punten zie ik daar niet.
Read more: https://www.computable.nl/artikel/opinie/cloud_computing/5003076/2333364/disaster-recovery-bij-een-public-cloud-iaas.html#ixzz2u3PMt2Na
De cloud timmermannen (Lennart & Henri) zouden er goed aan doen om bij de les te blijven, het gaat om IaaS en dus wordt er ruis ingebracht door de verwachtingen van SaaS te noemen:
“Cloud providers may find that making high-reaching promises around service delivery is the easy part; following up when things go bad is where it gets tricky.”
Betreffende SLA’s zijn inderdaad vele dingen mogelijk alleen dus niet bij de grote jongens waar het voor 99,999% toch ’take IT or leave IT’ is als ik leveringsvoorwaarden doorneem waarin opvallend vaak clausules aangaande overmacht zijn opgenomen. Cloud timmermannen zouden er goed aan doen om nog eens de lessen van Katrina te lezen:
“Everybody knows things break – it’s the nature of life. It’s how you respond to things breaking that sets you apart as a cloud service provider” – Chris Drumgoole, vice president of global operations Terremark
Dat sommige bedrijven afspraken maken die ‘Crap’ zijn wil nog niet zeggen dat dat SLA’s uitsterven, het lijkt me nogal ongefundeerd als ik kijk naar de initiatieven hierin om tot een ’template’ te komen voor cloud computing.
@Ruud
Als je het over ‘hot-pluggable RAID-units’ hebt met unieke ‘sellingpoints’ dan heeft het verder geen uitleg nodig wat bedoeld wordt. Als je stelt dat organisatie het moet inzien en er voor willen betalen dan heb je het naar mijn mening toch over een soort van overeenkomst;-)
@Pa Va Ke
Je hebt het over rigide (ridicule) contracten versus de wens van flexibilteit wat grote overeenkomsten heeft met je verhaal over de keus van legacy en welke zich niet alleen beperkt tot technologie. Vergeet niet dat vooral de hierarchische organisaties vanuit de ‘verkeerstoren’ visie werken met SLA’s. En inderdaad worden deze dus niet altijd opgesteld door de piloten die door de cloud moeten vliegen maar door verkeersleiders die alleen een blik werpen op de landingsbaan.
@Reza
Je denkt te moeilijk, neem bijvoorbeeld hele hype rond big data waar het niet om de applicaties maar de analyses gaat. Stellen dat applicatie en data onlosmakkelijk met elkaar verbonden zijn geldt zeker niet voor alle ongestructureerde data.
Dankjewel, Ewout, a.k.a. mister edge case, er werd over *AAS veel geroepen wat onjuist is (alleen per mail communiceren en geen maatwerk), daar reageerde ik op. Dit gaat inderdaad over IaaS.
Hi, een korte reactie op het artikel van Bart:
Als ik het goed heb doel jij in dit artikel op bedrijven die 3rd party cloud providers (IaaS) gebruiken als origin infrastructure en je wilt de mogelijkheden en beperkingen in kaart brengen m.b.t. Disaster Recovery (DR).
Los van het artikel en voor de goede orde:
a) Data Backup is geen DR
b) Data Backup zonder DR brengt traditioneel een RTO met zich mee van dagen/weken afhankelijk van hoeveelheid data, complixiteit en vooral beschikbaarheid en kunde van human resources.
c) DR geldt als een verzekering en wordt vaak enkel ingezet bij mission critical hosting
Mission critical applications worden in de meeste gevallen niet op public IaaS gedraaid, daar public IaaS gestandardiseerd is(incl. commodity servers (x86 wintel/linux) en bedoelt zijn voor de massa. Daarnaast hebben bedrijven met mission critical applicaties te maken met regulaties. Dus als DR bedoelt is voor mission critical apps en mission critical apps zelden op public IaaS draait is DR 9 vd 10 keer niet benodigd met public IaaS als origin. Een data backup is vaak afdoende, vooral als je beseft dat de primaire karakteristiek van cloud (IaaS) “on-demand” provisioning is en een infrastructuur dus in minuten kan worden opgezet; uiteraard afhankelijk van hoeveelheid data.
Voorbeeld bij Cloud IaaS provider Softlayer: Origin draait bij Softlayer Amsterdam, Quantastor (private dedicated backup server) staat in een van de andere 24 datacenters wereldwijd naar keuze en er wordt een automatische backup gemaakt van de origin. Daar er interconnectie is tussen alle datacenters betreft het interne traffic en is traffic daardoor kosteloos. In geval van een disaster in Amsterdam, wordt de data van de quantastor in de andere datacenter retrieved om binnen een paar minuten/uren een nieuwe infrastructuur te provisionen (ook hier in een datacenter naar keuze). Zodra datacenter in Amsterdam weer is hersteld zal er een migratie plaatsvinden naar Amsterdam.
In geval van “echte” DR m.b.t. zelf gecontroleerde origins dan geldt de volgende hamvraag:
“Hoeveel kost het als ik een dergelijke DR solution gebruik? En hoeveel kost het als ik deze DR solution niet gebruik en mijn origin ligt plat?” Calculeren…RTO/RPO bepalen…Solution kiezen. De kortste RTO/RPO komen momenteel voort uit cloud based DR solutions zoals SmartCloud VSR (Virtual Server Recovery) van IBM. Vanwege continue replicatie van computing servers, storage servers, Databases waarin elke minuscule wijziging in real-time wordt gerepliceerd naar een private dedicated omgeving in een Tier 3+ datacenter van IBM brengt het een RTO met zich mee van seconden. Vanwege 94 snapshots per dag brengt het een RPO met zich mee van 15 minuten. Alles kan worden gemonitord en gemanaged vanaf een enkele webportal waar o.a. een onbeperkt aantal testen kunnen worden geinitieerd wanneer je maar wilt.
Staat deze oplossing in de kinderschoenen? Nee totaal niet. Deze oplossing wordt door duizenden klanten wereldwijd gebruikt. Sterker nog, er bestaat alweer een nieuwere solution binnen het portfolio van IBM BCRS waarin we het geen DR meer kunnen noemen omdat er geen recovery aan te pas komt (negatieve RTO laten we maar zeggen) en is gebaseerd op predictive analytics (big data) o.b.v. parameters die IBM BCRS de afgelopen 25 jaar heeft verworven (BCRS bestaat sinds 1989) in combinatie met de parameters van de klant. Valt veel over te vertellen maar dan wordt het allemaal veel te lang 😉
Excuus als het commercieel overkomt, dit is niet de bedoeling. Ik werk voor IBM en ken de details van IBM en niet zozeer van andere providers.
PS Bart: ik vind onderstaande quote wel erg vreemd:
“Een veel gemaakte fout is dat wijzigingen aan de infrastructuur niet doorwerken in de dr-oplossing, met catastrofale gevolgen bij een werkelijke uitwijk.”
Als een DR oplossing niet alle wijzigingen doorwerkt, dan is het naar mijn mening simpelweg geen DR oplossing. Dat is namelijk wat een DR oplossing doet in de kern…repliceren.
@Lennart,
Je denkt toch niet dat ik hier (public website) iets ga roepen over de tekortkomingen van onze business partners en hun producten/diensten? We gaan zeker in een traject onze kennis, ervaring en advies met onze klanten delen maar sommige van onze business partners hier afkraken lijkt me niet handig!
Voor de rest kun je ook zelf aan de hand van mijn case hierboven nagaan tot hoeverre de door jou benoemde leveranciers aan die behoefte kunnen voldoen.
@Henri,
Je reactie vind ik een mooie aanvulling. Op een punt na, ik heb geen conclusie door getrokken naar “alle” SaaS leverancier.
Verder het realiseren van een BC/DR op papier is zeker heel anders dan dat ook in praktijk brengen. Pas bij BC/DR test komen lijken uit de kast. Dit is juist het doel van BC/DR test om onzichtbare zaken inzichtelijk te krijgen.
Maar…………… we zijn circa 31 reacties verder en ik zie nog steeds geen reactie, bemoeienis, begeleiding etc van de auteurzelf die Cloud Architect is en in 10x “ik” op zijn profiel heeft mooi uitgelegd wat hij allemaal kan!