

Stel, de provider waar je al jouw bedrijfsapplicaties hebt ondergebracht ondervindt een heftige storing. Het is inmiddels dag zes van de storing en de bedrijfsapplicaties zijn nog steeds offline. De provider is telefonisch en per e-mail volstrekt onbereikbaar en communiceert geen oplostermijn. Als dat het moment is waarop jij je realiseert dat je een plan had moeten hebben voor dit soort scenario’s, ben je te laat. Er zit niets anders op dan te wachten tot de provider de storing weer onder controle heeft en de dienstverlening wordt hervat.
De afgelopen weken heeft een dergelijk situatie zich voorgedaan bij een provider in Nederland. Ik heb diverse klanten van deze provider aan de telefoon gehad, met de paniek doorklinkend in hun stem. Voor deze klanten kon ik alleen iets betekenen als ze zelf over een kopie van de data en de applicaties beschikten, voor de meesten zat er niets anders op dan te wachten en ervan te leren. In dit artikel lees je welke mogelijkheden je hebt als afnemer van IaaS en waar jouw beperkingen liggen.
Er zijn diverse methodieken beschikbaar om de continuïteit van de applicaties te waarborgen in het geval van een storing in de infrastructuur van de provider. Het nadeel van de meeste van deze oplossingen is dat ze de medewerking van de provider vereisen voor de inrichting, het beheer en onderhoud, maar bovenal voor de daadwerkelijke uitwijk. En dat is nou precies het punt: de provider is onbereikbaar.
Private cloud
Idealiter kun je als klant zelf beslissen over de inzet van een disaster recovery (dr)-oplossing en kun je de daadwerkelijke uitwijk ook zelf initiëren. Bij het gebruik van een private cloud (IaaS) zijn er diverse mogelijkheden om een betrouwbare dr-oplossing te implementeren. Denk hierbij bijvoorbeeld aan:
- Stretched virtualisatie clusters (EMC Vplex / NetApp Metro Clusters).
- Storage gebaseerde replicatie in combinatie met geautomatiseerdedr- tooling (EMC Recoverpoint, HP Lefthand in combinatie met VMware vSphere Site Recovery Manager).
- Replicatie op virtualisatie niveau (Veeam Backup & Replication/Zerto Virtual Replication/Novell Platespin Migrate).
Public cloud
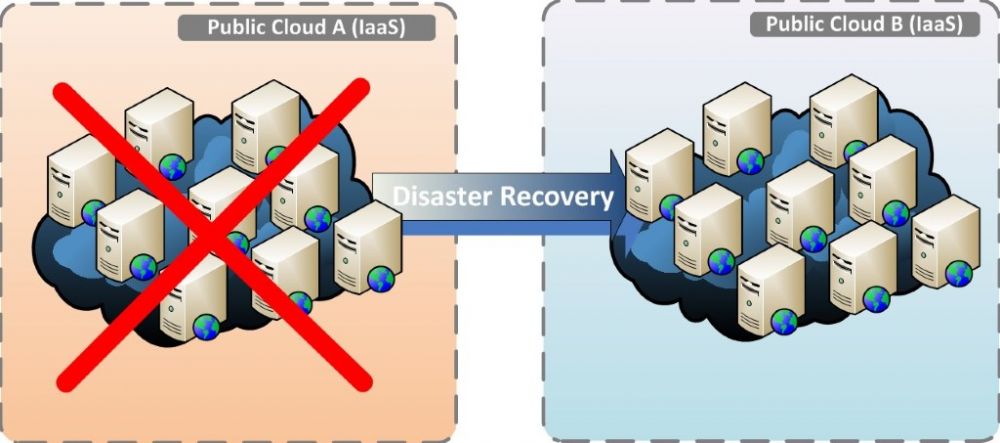
Bij public cloud (IaaS), waar er meerdere klanten op dezelfde fysieke infrastructuur draaien, zijn de mogelijkheden aanzienlijk beperkter en bovendien lastiger te realiseren. De professionelere providers hebben een dr-oplossing in het standaard product portfolio (wees bedacht op goed bedoelde specials). Zijn deze er niet, dan ben je aangewezen op de oplossingen die binnen het controledomein van jou als klant liggen. Meestal behelst dit alles vanaf de virtuele laag tot aan de applicatie. Replicatie op virtualisatie niveau is dan een mogelijkheid. Deze oplossingen zijn echter (op dit moment) nog onvolwassen als het gaat om public cloud (IaaS). Het resultaat is dus dat de disaster recovery in zo’n geval ingeregeld moet worden vanaf de operating system- en applicatie-lagen. Mogelijkheden zijn bijvoorbeeld het inrichten van replicatie op dataniveau en het clusteren van applicaties over meerdere cloud-providers. Dit vereist complexere ontwerpen voor data-synchronisatie en applicatie-clustering.
Wat me bevreemd is dat de meeste gebruikers van (public en private) cloud IaaS diensten ten onrechte denken dat de provider zorg draagt voor dr-diensten terwijl toch duidelijk uit het sla blijkt dat dit niet het geval is. De inrichting van dr is klant-specifiek en vereist een gedegen kennis van de infrastructuur van de klant. Providers die hierin excelleren hebben bij de inrichting van hun infrastructuur de juiste keuzes gemaakt en daarmee het fundament gelegd voor een goede recovery.
Mijn advies: leer van de situaties zoals die zich recent hebben voorgedaan en test of jouw huidige dr-plan voldoet aan de eisen van vandaag. Het is daarbij prima om te vertrouwen op de dr van je provider, maar test dan tenminste wel minimaal elke zes maanden. Besteed dan speciaal aandacht aan recente wijzigingen, gemaakt aan de applicaties en infrastructuur. Een veel gemaakte fout is dat wijzigingen aan de infrastructuur niet doorwerken in de dr-oplossing, met catastrofale gevolgen bij een werkelijke uitwijk.
Zelf volledig in control zijn? Richt dan een dr-oplossing in die binnen je controledomein ligt. De continuïteit van de onderneming ligt op de weegschaal. Handel snel maar vooral zorgvuldig.









@Ewout, dank voor je hartelijke welkom. Noem eens wat enterprise saas omgevingen die je gereversed lookup hebt? En noem eens een SaaS die langer dan zes dagenn uit de lucht is geweest? Waar de data heen gaan zegt natuurlijk niks over de beschik baarheid of disaster recovery van de diensten namelijk! Ik ben wel benieuwd waarover je het dan hebt, ook omdat je vindt dat ik altijd naar salesforce.com verwijs, maar ik noem iig het beestje bij naam! 🙂
@Ewout
Laten we het er op houden dat de meningen over daarover zijn verdeeld. Zoals ik al ooit schreef “DE” bestaat niet, en dat geldt ook voor SLA’s.
In een organisatie waarin je zowel productie, verkoop, kantoor, management, onderhoud, service en R&D hebt dan zijn er altijd afdelingen wier wensen niet binnen de SLA passen. In het geval waar ik op doel zijn de SLA’s vooral afgestemd op de kantoor-omgeving; voor een R&D omgeving is dit soms niet toereikend. De bedrijfskritische applicaties (SAP etc) zijn goed afgedekt, maar daar heeft R&D weinig mee van doen.
Wat je daarnaast dus ziet ontstaan is dat fabriek en R&D hun eigen omgevingen op beginnen te zetten zodat ze minder gebonden zijn aan de beheersorganisatie. Eigenlijk iets wat je niet wil, maar “the show must go on”
@Ruud & PaVaKe
Dank heren. Zonder jullie was het zeker niet zo gezellig om 1000 keer (nu 1001 dus) op deze site een reactie achter te laten 🙂
@Lennart
Ik denk dat je (in)direct doelt op grote SaaS spelers die misschien meer dc`s hebben. Maar als klant heb ik geen zin om altijd een dienst bij die grote leveranciers af te nemen. Dat komt o.a. doordat ik 1) hun SLA moet accepteren, 2) alleen via mail met hen mag communiceren, 3) geen maatwerk kan krijgen en nog meer.
Er zijn ook kleine spelers die me juist niet alleen deze punten geven maar ook kennis van mij sector hebben en applicaties aanbieden die goed bij mij business passen en ook nog verder op maat gemaakt kunnen worden. Denk aan SaaS-leveranciers van zorg-applicaties of onderwijs-applicaties.
Die jongens passen goed bij mijn business, cultuur, sector etc maar ze hebben de benodigde vermogen niet om hun diensten zoals die bij Google of AWS veilig te stellen.
In dit geval moet ik rekening houden met enorme kosten van een uitwijk, lees SaaS-escrow
@Ewout:
Ik snap je vraag niet! Wat heb ik aan mijn applicaties als data niet beschikbaar is en ook omgekeerd? Beschikbaarheid van een “dienst” kent op verschillende niveau`s verwevenheden en afhankelijkheden die je bij uitwijk moet realiseren. Dus of/of is geen optie, het moet en/en zijn.
@ Reza, Gefeliciteerd. Well Done.
Ik hik hier wat het artikel betreft een beetje op twee gedachten. Maar dat is meer de non-commercialist in mij. Als je niet de IT keten en de ‘eventualiteitn’ op je netvlies hebt, iets wat steeds meer en vaker gemeengoed blijkt te worden, dan moet je jezelf eens heel goed in de spiegel aankijken.
Disaster Recovery moet en mag niets meer zijn dan eenvoudigweg even doordenken, als gewoon standaard onderdeel van de gehele IT keten, welke maatregelen en scenario’s je kunt opstellen, gevallen zoals dit voorbeeld het hoofd te kunnen bieden.
Meer dan 24 uur….?
Ik denk dat de betreffende cloudleverancier dan al ten onder zal gaan aan schadeclaims. Tenminste, een beetje klant zal dat jruidisch goed dicht en aftimmeren me dunkt.
Redundancy
Die geld niet alleen zo zeer hardware matig maar juist procesmatig en procedureel voor elke onderneming. Toegegeven, vaak denkt men er niet zo over na maar komt men het tegen als het hen overkomt. Dan rijst meteen de vraag,’Wat zijn de kosten van Disaster Recovery’…. vs het verlies dat je loopt op het moment dat je vrijwel geheel afhankelijk opstelt van een cloud leverancier?’
Iets om weer eens terdege over na te denken gevolge dit artikel.
Dank Bart….
Nouja, mijn reactie kan hier ook nog wel bij 🙂 En Reza gefeliciteerd met je 1000+ reacties, en niet één zonder liefde!
– DR is een veelkoppig monster, een fuckupje in de DNS kan op afstand het zelfde aanvoelen als een vliegtuig op je datacenter.
– Uitwijken is één, terugkeren is een onderdeel wat zelden besproken wordt terwijl daar toch een 1 op 1 relatie is met het uitwijken!
– Een voorbeeldje SaaS bij Google. Stel het hele bedrijf gebruikt Google Apps. Google heeft een mega fuck-up, wat doe je dan? Zonder DR plan ben je het haasje. Door een externe dienst af te nemen (check de SLA en voorwaarden) kun je een 1 op 1 backup maken van al je data, bijvoorbeeld backupify. Daarmee heb je het verhaal meteen goed afgedekt. DNS van je mail omzetten naar bijv. O365, import wizards voor mail boxen, download en upload naar SkyDrive (rechten? Oops) en je hebt in ieder geval een plan. Is het perfect? Nee.
Wat betreft IAAS is het een stuk lastiger, maar geen DR plan is niet acceptabel. Als het misgaat kun je dat niet verdedigen. Dat een goed DR duur is mag duidelijk zijn, de meeste bedrijven zullen toch voor een tussenvorm kiezen waar haken en ogen aan zitten, maar die de kosten behapbaar houden.
Reza je drie punten in laatste reactie ben ik het oneens.
1) SLA is voor schildpadden (dank PaVaKe) dat geldt vaak ook voor kleine providers
2)Volstrekte onzin, pertinent, gewoon niet waar en is uit de lucht gegrepen.
3) Geen maatwerk klopt ook niet. definieer maatwerk.
@Reza; ik kan kan je wel helpen denk ik, bij welke saas leverancier mag je alleen met mail communiceren en kan er geen maatwerk?
@Henri; verbaast mij ook, er worden hier aannames als waarheid gedeponeerd die ongefundeerd zijn, maar ik zie dat Reza in de onderwijs en zorg actief is, daar is vaak On-Premise een groot goed, qua zorg kan ik me dat nog wel voorstellen qua data. Je kan trouwens inderdaad bij SaaS diensten zelf op elk moment je dataset exporteren, gescheduled en wel, ook hebben SaaS leveranciers alleen toegang tot meta data. Er hier gaat dit jaar nog heel veel ten goede veranderen!!
En @Reza; qua SLA, 99,xxx% zegt nog helemaal niks over de kwaliteit van de dienstverlening, daarom zie je ook andere metrics ontstaan zoals responsetijd, querysnelheid en aantallen transacties, SLA’s sterven ook uit in de SaaS / Cloud wereld, want de systemen zijn altijd up, maar dat zegt dus niks…
Dat is toch wel heel naief om te denken dat bij IaaS een provider voor recovery gaat zorgen. IaaS is niet anders dan je eigen datacenter maar dan op een andere plek en andere manier afgenomen. Aan de afnemer om iets met die IaaS te doen.
Goed stuk en fijne discussies! Toevallig gaat mijn volgende opinie (waarschijnlijk ma of di online) over beschikbaarheid en schijnveiligheid.