

Stel, de provider waar je al jouw bedrijfsapplicaties hebt ondergebracht ondervindt een heftige storing. Het is inmiddels dag zes van de storing en de bedrijfsapplicaties zijn nog steeds offline. De provider is telefonisch en per e-mail volstrekt onbereikbaar en communiceert geen oplostermijn. Als dat het moment is waarop jij je realiseert dat je een plan had moeten hebben voor dit soort scenario’s, ben je te laat. Er zit niets anders op dan te wachten tot de provider de storing weer onder controle heeft en de dienstverlening wordt hervat.
De afgelopen weken heeft een dergelijk situatie zich voorgedaan bij een provider in Nederland. Ik heb diverse klanten van deze provider aan de telefoon gehad, met de paniek doorklinkend in hun stem. Voor deze klanten kon ik alleen iets betekenen als ze zelf over een kopie van de data en de applicaties beschikten, voor de meesten zat er niets anders op dan te wachten en ervan te leren. In dit artikel lees je welke mogelijkheden je hebt als afnemer van IaaS en waar jouw beperkingen liggen.
Er zijn diverse methodieken beschikbaar om de continuïteit van de applicaties te waarborgen in het geval van een storing in de infrastructuur van de provider. Het nadeel van de meeste van deze oplossingen is dat ze de medewerking van de provider vereisen voor de inrichting, het beheer en onderhoud, maar bovenal voor de daadwerkelijke uitwijk. En dat is nou precies het punt: de provider is onbereikbaar.
Private cloud
Idealiter kun je als klant zelf beslissen over de inzet van een disaster recovery (dr)-oplossing en kun je de daadwerkelijke uitwijk ook zelf initiëren. Bij het gebruik van een private cloud (IaaS) zijn er diverse mogelijkheden om een betrouwbare dr-oplossing te implementeren. Denk hierbij bijvoorbeeld aan:
- Stretched virtualisatie clusters (EMC Vplex / NetApp Metro Clusters).
- Storage gebaseerde replicatie in combinatie met geautomatiseerdedr- tooling (EMC Recoverpoint, HP Lefthand in combinatie met VMware vSphere Site Recovery Manager).
- Replicatie op virtualisatie niveau (Veeam Backup & Replication/Zerto Virtual Replication/Novell Platespin Migrate).
Public cloud
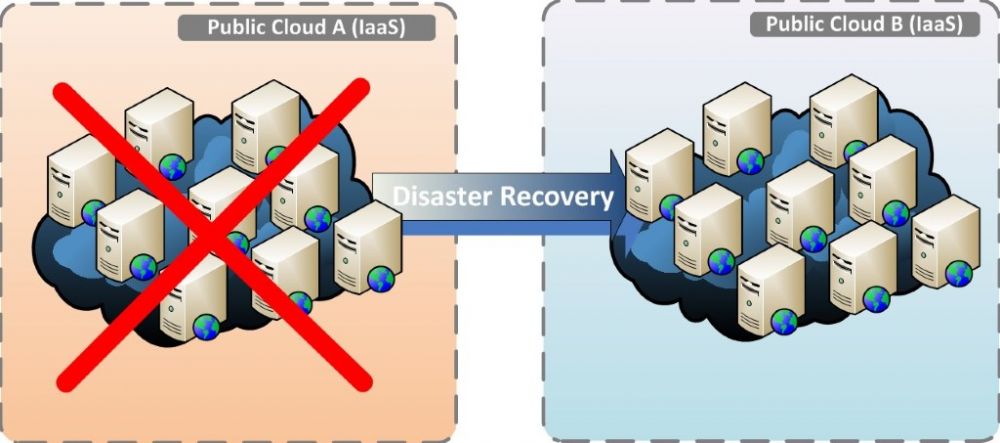
Bij public cloud (IaaS), waar er meerdere klanten op dezelfde fysieke infrastructuur draaien, zijn de mogelijkheden aanzienlijk beperkter en bovendien lastiger te realiseren. De professionelere providers hebben een dr-oplossing in het standaard product portfolio (wees bedacht op goed bedoelde specials). Zijn deze er niet, dan ben je aangewezen op de oplossingen die binnen het controledomein van jou als klant liggen. Meestal behelst dit alles vanaf de virtuele laag tot aan de applicatie. Replicatie op virtualisatie niveau is dan een mogelijkheid. Deze oplossingen zijn echter (op dit moment) nog onvolwassen als het gaat om public cloud (IaaS). Het resultaat is dus dat de disaster recovery in zo’n geval ingeregeld moet worden vanaf de operating system- en applicatie-lagen. Mogelijkheden zijn bijvoorbeeld het inrichten van replicatie op dataniveau en het clusteren van applicaties over meerdere cloud-providers. Dit vereist complexere ontwerpen voor data-synchronisatie en applicatie-clustering.
Wat me bevreemd is dat de meeste gebruikers van (public en private) cloud IaaS diensten ten onrechte denken dat de provider zorg draagt voor dr-diensten terwijl toch duidelijk uit het sla blijkt dat dit niet het geval is. De inrichting van dr is klant-specifiek en vereist een gedegen kennis van de infrastructuur van de klant. Providers die hierin excelleren hebben bij de inrichting van hun infrastructuur de juiste keuzes gemaakt en daarmee het fundament gelegd voor een goede recovery.
Mijn advies: leer van de situaties zoals die zich recent hebben voorgedaan en test of jouw huidige dr-plan voldoet aan de eisen van vandaag. Het is daarbij prima om te vertrouwen op de dr van je provider, maar test dan tenminste wel minimaal elke zes maanden. Besteed dan speciaal aandacht aan recente wijzigingen, gemaakt aan de applicaties en infrastructuur. Een veel gemaakte fout is dat wijzigingen aan de infrastructuur niet doorwerken in de dr-oplossing, met catastrofale gevolgen bij een werkelijke uitwijk.
Zelf volledig in control zijn? Richt dan een dr-oplossing in die binnen je controledomein ligt. De continuïteit van de onderneming ligt op de weegschaal. Handel snel maar vooral zorgvuldig.









Bart,
Hiermee mijn 1000e reactie op Computable.nl 🙂
Leuk artikel en misschien een “eye opener” voor sommige klanten!
Als je 6 dagen zonder je infrastructuur zit omdat je IaaS provider een probleem heeft dan moet je ff nadenken wat je met je ict gedaan hebt!
Wees blij dat je een telefoonnummer van je provider hebt. Als je je omgeving bij grote jongens neerzet dan krijg je eens geen telefoonnummer. Is de omgeving in de lucht dan krijg je als compensatie een deel van je huur (van 1 maand) terug! En hoe zit het met het verlies dat je business geleden heeft?
In je artikel geef je terecht aan dat de public cloud geen/niet voldoende ondersteuning biedt voor recovery zaken. Afhankelijk van wie je provider is heb je wel of geen recovery maatregelen in je dienstpakket.
Je voorstel/oplossing is gebaseerd op cloud escrow. Zeer terecht! Maar als je de kosten van cloud escrow in je business case meeneemt dan zou je zien dat je er helemaal niet voordelig uit bent.
Uitwijk in het geval van cloud behoeft een goede architectuur. Dwz dat je in ontwerpfase heel goed over cloud escrow moet nadenken. Het gaat niet alleen om de zaken aan de kant van je escrow-leverancier maar nog meer.
Ik probeer mijn reactie kort te houden. Je zal zeker voldoende reacties van andere mensen op dit artikel krijgen.
Tip: een mooie discussie over dit onderwerp (escrow):
Klant kan gevaar zijn voor je cloudleverancier
https://www.computable.nl/artikel/opinie/cloud_computing/4573553/2333364/klant-kan-gevaar-zijn-voor-cloudleverancier.html
Bart,
“Als dat het moment is waarop jij je realiseert dat je een plan had moeten hebben voor dit soort scenario’s, ben je te laat.”
Dat is een correcte opmerking, evenals dat je het moet testen maar grappige is dat deze uitwijktesten soms op een zodanige manier gedaan worden dat het niet representatief is voor een crisissituatie. En op het ‘moment suprême’ blijken vaak de sleutelpersonen niet bereikbaar, zijn er dingen niet goed overgegaan en nog een paar van die details die steeds vergeten worden.
Nu zie ik dat je vooral technische oplossingen opsomt vanuit de opslag die veel mogelijkheden bieden met ieder zijn eigenaardigheden en prijs. Maar juist hier gaat het vaak mis want het mag meestal niets kosten, classificatie van data en services ontbreekt meestal. Je haalt terecht aan dat IaaS provider niet zonder meer de DR inricht maar desondanks wordt dit wel verwacht, de cloud is toch het ultieme ontzorgen?
Dat is tenminste wat ons wijs gemaakt wordt door de ’tought leaders’ van sommige bedrijven en dus spreekt je afsluiting me aan, beheersbare kosten betekenen nog niet altijd een beheerbare bedrijfsvoering. Zeker niet als organisatie A de gehele ICT uitbesteed aan organisatie B die het werk verdeeld onder organisaties C en D welke vervolgens alles weer gaan hosten bij organisatie E.
Jij lijkt geïnspireerd door een recent voorbeeld met provider, ik door wat andere incidenten want BCM bestaat uit iets meer dan enkel Disaster Recovery op de technologie laag en mijn tip is dus het voorkomen van eilanden met daarop ieder zijn een eigen stam(hoofd).
@Reza
Je punt is genoteerd, heb binnenkort gesprekken hierover want volgens mij vergeet je nog wat. Kijkend naar hierboven gegeven lijntje van organisaties is de cloud namelijk een abstractie waarin nog een paar andere ‘schaduwen’ zitten. Vraag in deze is wat belangrijker is, de data of de applicatie?
Bart,
Leuk en zeer valide en actueel stuk. Waar voor dank.
@ Ewout,
Tja het is een beetje kip en het ei discussie. Zonder data is de applicatie nutteloos en vice versa ook.
Bart haalt goede oplossingen aan. Maar buiten de technologie speelt hier natuurlijk ook een discussie op politiek gebied. De organisatie moet het wel inzien en er voor willen betalen. En deze discussie duurt meestal langer dan de technologie keuze. En vaak wordt deze discussie pas gevoerd als men een keer uit de lucht is geweest. Dan komt het pas op de agenda te staan. Voorkomen is in dit geval beter dan genezen.
Even doen waar ik goed in ben: de domme eindgebruiker spelen:
Iedereen roept dat ik alles in de cloud moet draaien, want dat is zo handig, goedkoop, alles wordt voor me geregeld en ga zo maar door. Lofzangen over de cloud en alles wat eindigt op AAS te over op deze site.
Dus als domme eindgebruiker geloof ik dit, en wil me laten ontzorgen en kies een cloud-leverancier voor al mijn diensten.
En dan lees ik nu dat ik me als eindgebruiker ineens druk moet gaan maken over disaster recovery, replicatie lagen en weet ik veel wat voor moeilijke technieken.
Als klant zou ik me dan alles behalve geholpen voelen met de cloud-oplossingen.
Misschien toch maar weer mijn eigen omgeving inrichten?
@reza
ik sluit me aan bij Ruud, een mooie mijlpaal bereikt, met vooral veel zinnige reacties
@Pa Va Ke, ik snap dat je je zorgen gaat maken bij al deze horrorverhalen, maar bovenstaande artikel gaat over je eigen bedrijfsapplicaties in een cloud-omgeving draaien, in plaats van bedrijfsapplicaties als dienst afnemen, wat Software as a Service wordt genoemd. De meeste bedrijfsmatige SaaS oplossingen hebben real-time replicatie in meerdere datacenters, dus daar speelt dit probleem niet, er valt zelf namelijk weinig te recoveren, mocht de dienst niet beschikbaar zijn.
@Ruud
*zucht*
Ga nou eens die cursus ITIL doen, want volgens mij staat in de SLA niet hoe je iets bereikt maar wat je bereikt, liefst tegen laagst mogelijke kosten want vaak is IT gewoon een costcenter. Mag ik het even ‘plat’ slaan naar RPO/RTO per dienst?
En betreffende politiek kan ik simpel zijn, if you pay peanuts you get monkeys.
Pa Va Ke speelt de domme eindgebruiker, als ik me niet vergis hoeft hij daar niet zoveel moeite voor te doen want wat hij naar voren brengt is ongeveer het niveau van de gemiddelde IT regiseur waarover tegenwoordig zoveel gesproken wordt. En deze ‘digitale nitwits’ hebben echt geen idee van wat er allemaal aan de onderkant van de architectuur gebeurt, meesten maken niet eens een back-up want ze vertrouwen volledig op de beloften die gedaan worden door de provider.
Leuk dat Lennart ook mee doet in de discussie maar juist hier zie je de ruis ontstaan doordat gedacht wordt dat er SaaS afgenomen wordt terwijl het uiteindelijk om IaaS gaat. Zie mijn eerdere reactie aangaande het lijntje van organisaties want sommige SaaS providers hebben namelijk de techniek gewoon uitbesteed. Een reversed IP lookup laat al gauw zien waar de data precies landt, wie er ook op de server zitten en onder welke voorwaarden de ‘back-end’ geleverd wordt. Been there, seen that and done IT….
*bonkt met hoofd op tafel*
Als je er niks voor wilt betalen moet je er niets van verwachten, de cloud is namelijk niet goedkoper alleen maar sneller. Helaas geldt dit ook voor de replicatie van fouten want om een eerdere uitspraak nog maar eens te herhalen: ‘History doesn’t repeat itself, but it does rhyme’ – Mark Twain.
@Ewout: het goede nieuws: het is vooral gespeeld 🙂
Maar de beloften van de provider zoals jij ze noemt is wel hetgeen de MKB-er, die een betaalbare oplossing zoekt voor zijn IT omgeving, doet besluiten voor een bepaalde oplossing te kiezen. Terecht of niet, hij gaat er dan van uit dat e.e.a. goed geregeld is. Met uitzondering van de groenteboer wellicht wil hij zich niet druk maken over wat voor SLA dan ook. Als IT professional ben je misschien met dit soort dingen bezig omdat dit tot je (kern-)competenties hoort, maar voor veel anderen in IT een hulpmiddel.
De gemiddelde IT regisseur die jij noemt is misschien wel een heel ander punt van zorg. Steeds meer diensten, ook IT diensten, worden ingekocht door commerciële afdelingen op basis van prijs en SLA’s. Wat aan de onderkant zit weten ze inderdaad vaak niet. Zij betalen het liefst de peanuts, want dat begrijpen ze, en daar worden ze op afgerekend.
Ik ken ITIL (en heb er mee gewerkt), ik ken SLA’s, maar mijn ervaringen met dit soort bouwwerken is vooral dat men dit gebruikt om zich achter te verschuilen. Als ik NU een probleem heb, maar de IT-regisseur een SLA bedongen heeft waarin 5 werkdagen staat om mijn probleem op te lossen, dan wordt ik niet vrolijk als ik daardoor 5 dagen moet wachten.
De service- en help-desk nachtmerries zijn bij menigeen bekend, en dit soort overhead wordt in stand gehouden door de bureaucratie.
Misschien ben ik hierin ouderwets, maar doe mij maar de systeembeheerder die je rechtstreeks kunt bellen, die snapt wat jou probleem is en je kan helpen of even langs kan komen. Dat werkt toch echt wel een stuk lekkerder dan de helpdesk in verweggistan, de 2e lijns helpdesk in weer een ander land en het excuus dat het niet kan omdat dit niet in de SLA staat.
Maar dat terzijde
@Pa Va Ke
Misschien ben jij geen kritische component in de keten, jouw probleem is niet urgent genoeg voor de business?
Ewout,
Ik heb het woord SLA voor zover ik kan terug lezen niet gebruikt. Dus ik snap je reactie niet helemaal. Maar misschien had je je leesbril niet op 🙂
En het plat slaan naar een RPO/RTO per dienst ligt politiek altijd gevoelig. Als je deze discussie aan gaat met de klant is alles super belangrijk. Maar hier komt men snel op terug als men ziet welk prijskaartje er aan vast hangt. Dit is in mijn optiek 1 van de meest tijdrovende discussies die je maar kan hebben.
Classificeren van de applicatie en de daarbijhorende data is en blijft hier key. Niet alles hoeft namelijk even snel weer up and running te zijn. En vergeet hierbij niet de hele keten. Want er hoeft maar 1 zwakke schakel tussen te zitten en je bent de pineut.