

Het is begonnen met SaaS, gevolgd door cloud en social media en grootschalig wetenschappelijke (gezondheid en ruimtevaart vooral) onderzoeken. Big data is geboren, big data neemt een enorme vlucht, big data is een evolutie in de geschiedenis…
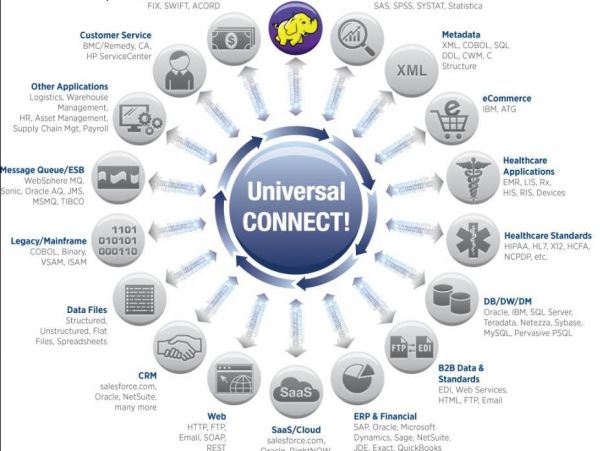
Zowel de huidige telecomconsumenten als de ict-ontwikkelingsmarkten gaan straks net iets anders functioneren dan wat wij gewend zijn. De klassieke manier van applicaties bouwen, data beheren en opslag worden geschiedenis. Alles wordt snel, eenvoudig, voor iedereen bereikbaar en visueel. Alles draait om van tevoren te weten wat straks aan consumenten geboden wordt.
Het motto: Business In Future
Hardwareproducenten willen kleinere, zeer snelle dataopslag en processors maken met nog minder investering voor de consumenten. Dat komt doordat elk jaar data die opgeslagen is 40 procent groeit. Wat zal dat dan straks voor mkb’ers en grotere bedrijven betekenen? Of voor bedrijven die direct te maken hebben met partijen zoals Bol.com, Wehkamp, luchtvaartmaatschappijen, telecombedrijven, et cetera?
Wij zullen ons moeten voorbereiden op deze aankomende innovatie, ons bewust zijn van wat voor soort bedrijfsdata wij thuis hebben en wat die data doet voor de visie en strategie van het bedrijf en wat dit betekent binnen gewenste investeringsgrenzen. Aan de ene kant willen wij meer en meer kwalitatief goede data uit de enterprise gegevens halen, aan de andere kant wil men maatregelen nemen voor de razendsnel groeiende dataopslag.
Iedereen heeft het er tegenwoordig over dat big data een hype wordt, maar men weet weinig over big data. In enkele woorden is big data alles wat gedigitaliseerd is. Dat kunnen bijvoorbeeld simpele supermarktboodschappen zijn, opnamen met de securitycam, de sales lead die via bedrijfswebpagina gegenereerd is of gegevens uit social media. Maar waarom is het ‘big’?
Dit is omdat ongestructureerde data wordt gekoppeld aan gestructuurde data. Dataopslag groeit per jaar meer dan 40 procent op dit moment. Dat betekent dat beheren van die data of processing van die data ook duurder wordt. Ook zijn grote data sets qua volume te groot om binnen traditionele datastorage met processors te behandelen. Met de nieuwe big data-technieken zijn massadata in stukjes geknipt en geclusterd, zodat de dataprocessnelheid is verbeterd en data-analytics als geheel is geïmplementeerd.
Een traditioneel enterprise datawarehouse zal als big data-oplossing 2,5 keer meer datastoragekosten met zich mee brengen. Real time analysis kan bereikt worden, zodat enterprises ook realtime acties kunnen ondernemen. Hun klanten kunnen ook profiteren van predictive analytics. Als er bijvoorbeeld een storm verwacht wordt, beïnvloedt dat de datakwaliteit in datatransmissie bij betalingen. Dat is van belang voor banken. Daarnaast krijgen bedrijven meer inzicht in hun business en willen ze de datasilo tussen de businessafdelingen afbreken. Zodoende krijgt het C-level management breder inzicht in de zaken, terwijl businessafdelingen nog betrouwbaardere gegevens ontvangen. Zodoende wordt nog meer Ddata breder gevisualiseerd.
Wat zal dat straks voor bedrijven betekenen? Het management moet inzicht krijgen in datatransparantie, moet data kunnen relateren, moet data veilig kunnen stellen voor binnen en buiten de enterprise. Het allerbelangrijkste is om consumenten tijdig te informeren over het productieportfolio, dynamische prijsstelling en het verbeteren van de klantenservice.
Voor het grote publiek betekent dit bijvoorbeeld op maat aangemaakte medicijnen, extra veilig autorijden, etc., maar je moet wel blijven opletten dat je privégegevens en productvoorkeur niet op internet bekend is. Voor de technologie betekent dit dat de snelheid in wetenschappelijke analyses en onderzoeken enorm toeneemt. Project die voorheen in meerdere jaren gerealiseerd werden, kunnen nu binnen enkele dagen afgerond worden, zo ver is het technologie.
Om tot predictive analytics te komen, zijn er binnen big data analytics twee methoden samengevoegd. Om patronen te vinden heb je machine learning code en data mining. In machine learning code worden ‘bekende’ waarden en patronen in data gezocht. Deze worden wat vaker in wetenschappelijke onderzoeken gebruikt, zoals die van Cern. In data mining worden ‘onbekende’ waarden en patronen gezocht, proberen we nieuwe waarden te creëren uit onbekende of zoeken we oorzaken voor bekende events en patronen.
Business intelligence is een onderdeel van big data, maar bi is niet voldoende om grootschalig data te analyseren, definiëren of realtime analytics te kunnen doen. Ook kan je niet realtime acties ondernemen tot de einddeur bij de klant. Met predictive analytics van big data kunnen dit soort zaken wel gemeten en zichtbaar gemaakt worden.
De grootste handicap in big data is het gat tussen businessmanagers en ict. Duidelijke big data-strategieën moeten opgesteld worden, er moet geanalyseerd worden welke data in het bedrijf aanwezig zijn en moet de hoeveelheid van die data voldoende kwalitatief zijn voordat er met big data-projecten begonnen wordt.
Soms kan het zijn dat het businessdoel van het bedrijf niet in big data-mogelijkheden past. Dan zijn er concrete targets nodig vanuit de business. Die kunnen vanuit ict worden ingevuld met aanvullende requirements-analyses.
Meer over dit onderwerp is te lezen (in het Engels) op http://www.facetobusiness.com/bdt/images/arzubbigdatawhitepaper.pdf.









Ook in dit artikel wederom geen uitleg waarom Big Data geen hype is.
“Het management moet inzicht krijgen in datatransparantie, moet data kunnen relateren, moet data veilig kunnen stellen voor binnen en buiten de enterprise.”
Hier zit precies het pijnpunt van de big data hype: je moet wel precies weten wat je er uit wil hebben en dat is veel moeilijker dan iedereen verkondigt. Ook hier geldt weer: IT moet geen doel op zich zijn!
“Het allerbelangrijkste is om consumenten tijdig te informeren over het productieportfolio, dynamische prijsstelling en het verbeteren van de klantenservice.”
Bij juiste bedrijdsvoering heb je helemaal geen big data hiervoor nodig.
Ben Elton schreef in 2008 het boek “Blind Faith”. De hoofdpersoon in dit fantastische verhaal heeft als baan het zoeken van de meest onzinnige (nog niet eerder gevonden) relaties tussen data. Een aanrader…
Ik ben het met Jeroen eens.
Wat bedoelt de auteur precies met gestructureerde en ongestructureerde data? Data is mooi, maar het is pas werkbaar als het te gebruiken is, en dan is het informatie.
Er wordt al heel lang met grote stukken data gewerkt (marktonderzoeken, epidemiologie etc.), maar sinds dat er computers zijn en er steeds betere processors komen, kunnen we de grote datahoeveelheid sneller onderzoeken.
Maar data is nog geen informatie.
IT is hierbij slecht een hulpmiddel om van data informatie te maken, masar dan moet je wel geschikte data hebben.
Anders ben je nog steeds een fool met een tool.
Arzu,
Predictive analytics is een pseudowetenschap want bij betrouwbare gegevens gaat het niet om de data of de omvang maar de foutloze meting en de controleerbaarheid. Een voorbeeld:
1. Er staat een bord langs de weg met 100.
2. Mijn snelheidsmeter geeft 120 aan.
Eén en twee bij elkaar opgeteld is de informatie dus dat ik te hard rij en met geautomatiseerd sanctieproces van trajectcontrole daarom een boete krijg.
Dezelfde case maar nu met andere parameters:
1. Er staat een bord langs de weg met 100.
2. Mijn snelheidsmeter geeft 100 aan.
Eén en twee bij elkaar opgeteld is de informatie dat ik NIET te hard rij maar toch krijg ik een bekeuring omdat er een fout zit in de software waardoor mijn auto aangezien wordt als vrachtwagen of bestelbus.
Nu zal trajectcontrole misschien geen best voorbeeld zijn van Big Data maar het gaat erom dat meetfouten tot vervelende consequenties kunnen leiden. Iets waar trouwens het CERN ook achter kwam toen ze te vroeg iets riepen over de snelheid van het licht door een meetfout.
Snelheid en betrouwbaarheid gaan dan ook vaak slecht met elkaar samen, zeker als ook de reproduceerbaarheid ontbreekt. Predictive analytics voor business managers is dus gewoon astrologie, niet meer dan een horoscoop. En stellen dat grootste handicap in Big Data het gat tussen business(managers) en IT is lijkt me van een tunnelvisie getuigen omdat de spanning vooral zit in te kleine budgetten.
Iedereen snapt wel dat als je dingen weet (data – feiten – bewijs), dat je op basis daarvan betere beslissingen kunt maken als dat je het alleen maar op gevoel doet.
Maar met dit soort artikelen zie ik sterke relatie met cloud computing eerder. Iedereen roept er van alles over, maar doordat er maar weinigen concreet zijn blijft het allemaal nodeloze bla bla en lege retoriek.
“Big data neemt een enorme vlucht” – wat zegt dat nou? Wie zit daar nu op te wachten?
Pak een specifiek onderwerp en schrijf daar iets zinnigs over, ik zal een paar suggesties doen:
– Hoe realiseer je “machine learning code”
– Waar sla je je data op en tegen welke problemen loop je daar aan?
– Noem voorbeelden waarin “big data” succesvol is en beschrijf wat daar bij kwam kijken
– Welke technieken gebruik je om real time analyses te doen
– Welke tools zijn er momenteel en wat daar de zwakke en sterke kanten
– Wat is een stappenplan om waarde te halen uit Big Data?
– Welke technieken voor verwerking hebben de toekomst?
Zo maar wat suggesties die in mijn ogen hout snijden. Ofwel, noem man en paard als je over big data praat.
En als teaser, onderbouw jouw stelling “maar bi is niet voldoende om grootschalig data te analyseren”
Arzu,
Welkom! En goed te zien dat je bent gaan schrijven. Echter deel ik wel de mening van Henri. Je artikel is wel heel erg hoog over. De tips die Henri geeft zijn zeer bruikbaar. Dus ik kijk uit naar je 2e artikel waar je hier verder op in kan gaan. Want big data is een hot topic.
:), meer te lezen is in het Whitepaper. Daar is het breder opgepakt. uitgelegd waarom het geen hype is.
– Unstructureerd data kan door meerdere data chanells gegeneerd worden
– Her gaat over Data Transparancy, afbreken Silo’s, Visualiseren, Reduceren kosten met slimme opslag & slimme Analytics en reflecteren in Social Media als het wens is.
– De grootste handicap in Big Data is dat er weinig uniform standards vast kunnen gelegd worden. Elke Big Data case is Unique, per business segment & Business strategie factoren & Data channels componenten zijn verschillend per situatie.Bedrijven zullen duidelijke Big Data visie hebben, niet zomaar sprongen naar een grote data ocean zonder een goede voorstudy analysis.
@Arzu Bedankt voor je reactie
Ik dacht al dat er in je WP meer zou staan.
Ik zal het dit weekend bestuderen en dan krijg je komende week feedback 🙂
Mooi dat je het oppakt binnen Computable
@arzu
Ik snap de Whitepaper-insteek en daarmee het gebruik van een aantal “mainstream”-termen welke bij het concept “Big Data” horen. Ik had alleen een wat verdere uitdieping van het concept graag terug willen zien in dit artikel. Maar mogelijk wordt daarmee de doelgroep van computable.nl niet bereikt.
Ik ben daarom ook van mening, net zoals Henri Koppen, dat dit artikel met een meer praktische invulling geschreven had kunnen worden. Bijvoorbeeld de toepassing van NoSQL, Hadoop bij een grote corporatie zoals Facebook of Google. Daarnaast zou een voorbeeld/voorstel van een BigData-model een welkome additie zijn met daarbij de vraag welke bestaande (of nog te ontwikkelen) modellerings-technieken hier mee uit de voeten zouden kunnen. Hetgeen discussie op gang kan brengen.
Wat betreft het concept “data mining” en dit toe te passen op ongestructureerde data, ben ik het niet helemaal met je eens. Wanneer men, op welke manier dan ook, tracht ongestructureerde data (inhoud van een tweet, facebook-post, product-review o.i.d ) middels algoritmen te analyseren, welke veelal onder de noemers “social mining”, “opinion mining”, “linguistic engineering” en “text-mining” vallen, zal er altijd een bepaalde structuur aan de “ongestructureerde” data worden geven. Hetgeen de term “ongestructureerde data” ter discussie stelt.
Een stelling zou kunnen zijn dat er enkel met grote gestructureerde datasets wordt gewerkt. Maar deze worden niet ongestructureerd /real-time geanalyseerd daar algoritmen uitgaan van variabelen en specifieke mathematische functies. Hetgeen een dataset vereist welke dusdanig gestructureerd is zodat een algoritme er mee kan werken.
daarnaast zal data inderdaad in de juiste context geplaatst moeten worden om hier naar te kunnen handelen. Enkel hebben bedrijven al de grootste moeite met het interpreteren van data welke in hun IT-systemen zit, laat staan externe “ongestructureerde” data uit andere omgevingen. Dit wordt ook wel de “Information Gap” genoemd.
Wat vind je van bovenstaande stelling?
Hoe zou het komen dat ik bij het lezen van:” Alles wordt snel, eenvoudig, voor iedereen bereikbaar en visueel.”
een flashback naar 20 jaar geleden krijg?
Beste Arzu,
Aangezien je opinie een samenvatting van je White Paper (WP) is blijven meest gestelde vragen nog steeds onbeantwoord. De opsommingen geven dus even weinig onderbouwing en gaan al helemaal niet in op de keerzijde van ‘big’ waardoor er een tunnelvisie ontstaat. Argument dat we silo’s af moeten breken heb ik trouwens al eens gehoord en SOX was hier een antwoord op.
Technisch is er misschien veel mogelijk maar juridisch en maatschappelijk blijven andere domeinen die vaak nog weleens vergeten worden. En nu bekend wordt dat automatische sanctieproces van trajectcontrole niet alleen software fouten kent maar ook extra administratieve kosten om deze te herstellen vraag ik me af wat (of voor wie) nu de winst en het verlies hiervan is.
Maar ik wens je veel data;-)