
Verzekeraars hebben heel wat it in huis en daar wordt veel aan getest. Dat vraagt om consistente testdata over de gehele keten. Niet alleen bij verzekeraars, maar bij elke organisatie met data-intensieve it-ketens. Goede testdata krijg je niet cadeau en bestaat uit ‘zelf gemaakte’ testdata in combinatie met productiedata. In deze bijdrage enkele overwegingen daarbij.
Als Nederlanders zijn we de afgelopen weken nogal bezig geweest met onze zorgverzekeringen. Na alle dringende adviezen heb ik m’n zorgverzekering en die van vrouw en kinderen ook maar eens tegen het licht gehouden. Conclusie: eigen risico maximaal (was al zo) en aanvullende verzekeringen minimaal (was ook al zo). Veel goedkoper kan het niet, maar toch schrok ik ook dit jaar weer van de premie.
De zorgverzekeraars schrikken ook omdat we massaal voor dat hogere eigen risico kiezen. Op termijn zullen de premies hierdoor omhoog moeten. Een betere bevestiging dat een maximaal eigen risico niet lucratief is voor de verzekeraar en dus wel voor de verzekerde kunnen we niet hebben. Gemiddeld genomen natuurlijk. Want je zult net zien dat ik dit jaar wel met mijn bumper tegen mijn voorganger en met mijn tanden tegen het stuur knal terwijl ik – conform mijn goede voornemens strikt handsfree te bellen – even niet genoeg op het verkeer let.
Maar dat terzijde, want ik wou het eigenlijk over iets anders hebben: testdata. Momenteel help ik een van de grote Nederlandse zorgverzekeraars om hun testproces verder te stroomlijnen en dan is nadenken over testdata onontkoombaar. De veranderende wetgeving en de competitieve markt zorgen voor een continue stroom van wijzigingen in de complexe administraties van verzekeraars, banken en andere trotse eigenaren van complexe it-landschappen. Snelheid en kosteneffectiviteit zijn daarbij anno 2013 geen luxe meer, maar een kwestie van ’to be or not to be’.
Testdata in de keten
Grip op dit dynamische proces vergt een slimme testaanpak en goede testdata. Goede testdata is consistent en referentieel integer over de gehele keten en voldoet aan de Wet Bescherming Persoonsgegevens. Het creëren en beheren van testdata is nogal een uitdaging. Vooral ook omdat de set productiedata meestal te groot is voor flexibel-testen en ook om privacyredenen niet zonder meer kan worden ingezet. Een discussie die ik vaak hoor is: moeten testers hun testdata zelf maken of kunnen ze productiedata gebruiken? Mijn antwoord is: allebei. Hieronder de redenen waarom.
Er zijn veel redenen om zelf ‘fictieve’ testdata te maken en naar mijn mening zijn dit de belangrijkste: • Nieuwe situaties: Testen van nieuwe functionaliteit vraagt vaak (niet altijd) nieuwe datacombinaties, die in productie nog niet bestaan;
• Structuur en dekking: Systematisch’“Risk & Requirements based testen’ vraagt om een gestructureerd testontwerp waarin de belangrijke functies en datacombinaties systematisch worden gedekt, wat met een onvoorspelbare set productiedata niet lukt;
• Negatief testen: je wilt ook testen dat bedoelde of onbedoelde rare en verboden combinaties netjes worden afgevangen. Negatieve testdata zul je niet of nauwelijks in een productiedump aantreffen.
Waarom testen met productiedata?
Ook hier: er zijn veel goede redenen om productiedata te gebruiken en dit zijn een paar belangrijke:
• Relevantie: de in de praktijk meest voorkomende producten en datacombinaties zijn het meest relevant om grondig te testen;
• Exoten: vreemde combinaties die je wellicht niet had verzonnen maar in de praktijk blijkbaar wel voorkomen pak je mee;
• Polis- en claimhistorie: productiedata bevat een brok historie die slechts met grote moeite en tegen hoge kosten in een testomgeving opgebouwd kunnen worden;
• Snelheid: Je kunt soms (niet altijd) snel een redelijk complete test optuigen met productiedata waarmee je de belangrijkste risico’s waarschijnlijk wel afdekt;
• Volume: Veelal wil je ook testen met grote volumes met een realistische spreiding, ook voor Performance, Load en Stress testen.
Slimme testdata: combinatie
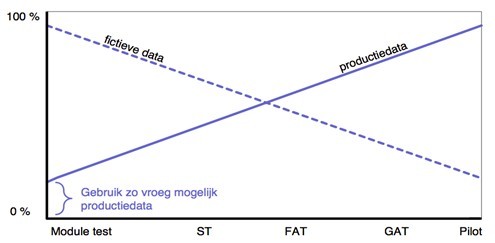
Wat mij betreft is een goede set testdata altijd een combinatie van zelf ontworpen data en productiedata. De ene keer meer van het ene en de andere keer meer van het andere. In zijn algemeenheid geldt: Hoe verder het testen vordert, hoe meer je je omgeving én je data ‘als het ware productie’ wilt hebben. Nevenstaande figuur illustreert dat. Gelukkig zijn er steeds meer goede tools voor testdata management met allerlei voorzieningen voor subsetting en depersonalisatie.
Desondanks blijft het maken en beheren van testdata in een complex itlandschap een uitdaging waarvoor je al je professionele registers moet opentrekken. Maar met ervaring, gevoel voor maatwerk en de business en met inzet van de goede tools komen we steeds verder. Ik draag daar met mijn collega’s met plezier aan bij en verheug me op een creatief 2013, ook in dit opzicht!









Als consultant heb je het voordeel dat je in meerdere keukens hebt mogen kijken. En zo heb ik dat ook gedaan bij oa verschillende financiele instellingen.
Wat testdata betreft durf ik beide handen in het vuur te steken dat het gros van de verzekeraars met een kopie van produktie data werken. Misschien dat in sommige de persoonsgegevens zijn geanonimiseerd maar ook dat zal eerder een uitzondering betreffen.
Het is overigens wel een goed praktijktest maar niet volledig dekkend qua mogelijkheden. En dan zie je ook vaak bij veranderingen in de programmatuur dat deze test set mogelijkheden open laat voor combinaties die nieuw zijn. Aansluitend zijn deze combinaties voor het personeel vaak ook nog nieuw dus eventuele fouten worden dan vaak ook nog niet eens opgemerkt en kan dat alle gevolgen van dien hebben. (Ergste geval, onjuiste dekking!)
Dus was dat betreft sluit ik me van harte bij Egbert aan. Alleen weet ik wel dat dit in de praktijk vaak nog niet gemeengoed is.
Egbert,
Goed dat je dit onder de aandacht brengt. Het klopt dat er een blijvende behoefte is aan het gebruik van productie-like testdata. Met name vanwege de representativiteit en beschikbaarheid.
Het is zeker goed om te zien dat er tools op de markt verschijnen, die hierin optimaal kunnen ondersteunen. Juist ook over de keten van systemen heen. Hiermee heb ik zelf bij verschillende zorgverzekeraars al ervaring opgedaan en zie dat dit het ontwikkel- en testproces perfect kan ondersteunen. Aanvullend kan je door inzet van tools voor het subsetten van testdatabases (waarmee je met kleinere sets kan werken), direct het voordeel van sneller testen en beperken van resources behalen.
Je ziet in de praktijk dat dit snel tot aanzienlijke kostenbesparing kan leiden.
Hilbrand
Egbert,
Productiedata is vaak op eenvoudige manier te anonimiseren, zeker als deze opgeslagen ligt in relationele databases. SQL is tenslotte gewoon een vorm van algebra en met enkele slimme formules kun je van informatie ook weer gewoon gegevens maken. Dat dit vaak niet gedaan wordt of met een algemeen bekende verschuiving is geen nieuws, net als dat testsystemen vaak minder goed beveiligd zijn. Betreffende je voorstel om productiedata met fictieve data te mengen hoop ik dus wel dat eerste vooraf afdoende geanonimiseerd is.
In het verleden heeft mijn compagnon een Personen Generator gemaakt die met sofinummers, namen en adressen niet bestaande leuke sets maakte die functioneel wel klopte.
Je kunt ook nog testen op productie (zei ik dat hardop?)
Of een soort laadstraat maken die steeds met een algoritme een leuke set overneemt,maar wel anonimiseerd. Maar net als Sjoerd zie ik dat men vaak die moeite niet neemt. Belangrijk aspect is dan wel dat je in ieder geval op eenzelfde veilige manier werkt als met de productie.
Wat betreft het zelf maken van testdata zet ik wel een vraagteken bij negatief testen. In feite is testdata altijd in eerste instantie neutraal en kan het 2 kanten op: goed of fout. Gaat het goed, dan zijn het gevallen voor de regressietest; gaat het fout, dan zijn het gevallen voor de ontwikkelaar en/of de ontwerper en komen ze na aanpassing en hertest uiteindelijk ook in de (geautomatiseerde) regressietest terecht. Het doel van test is dus te komen tot een optimale testset waarmee de correcte werking van een applicatie kan worden aangetoond. In die zin kan het testen dus op geen enkele wijze als negatief of destructief worden gekenmerkt.
Gebruik van productiedata hoeft geen probleem te zijn, zolang het maar gedepersonaliseerd is.
Dit depersonaliseren gaat echter nog veel verder. Wanneer er bij de klant een probleem optreedt, en er moeten log- of tracefiles gegenereerd worden uit het systeem, dan moeten ook de persoonlijke gegevens geanonimiseerd worden.
Het voordeel van productiedata is dat nagenoeg alle mogelijkheden voorkomen, ook die waar je als tester even niet aan gedacht hebt.
Er zijn voorbeelden bekend waar een vrouw van 107 jaar oud een oproep kreeg zich te laten vaccineren; wat normaal bedoeld is voor kinderen van 7 jaar…..
p.s.: dit verhaal is vele malen beter dan je vorige
dag Egbert,
Om het aantal comments wat meer in evenwicht te brengen met je vorige blog,…
Met genoegen had ik dus wederom commentaar willen geven echter van dit onderwerp heb ik de klok wel horen luiden maar weet ik niet waar de klepel hangt (hardware klok..), want het zit buiten het vakgebied waar ik iets van denk te weten.
Allemaal bedankt voor jullie interessante en positieve reacties!
@Sjoerd: inderdaad, er wordt nog heel wat getest met niet-geanonimiseerde productiedata, maar het wordt wel minder.
@Hilbrand: Dank je! En helemaal eens. Netjes ook dat jij als leverancier van goede tools geen reclame maakt hier. Kan ik nog wat van leren (zie mn bijdrage ‘Geen software in de kerk’).
@Ewout: ja, anonimiseren is belangrijk, dat schrijf ik vrij duidelijk imho. Soms is het vrij eenvoudig te doen inderdaad, maar niet altijd.
@Henri: Software in de kerk en vloeken in de kerk zijn slecht. Vroeger stond Testen in Productie ook in dat rijtje, maar dat verandert gelukkig. Tip: noem het geen testen.
@Jack: ‘negatief testen’ klinkt negatief, maar is gewoon een hele positieve activiteit. Zo noemen we het nu eenmaal.
@Pavake: inderdaad, er zit meer aan vast dan je denkt. En bedankt voor je compliment. Laten we het erop houden dat m’n andere bijdrage gewoon een heel ander karakter en intentie had.
@Maarten, toch leuk dat je reageert, bedankt!
Nog een aanvulling op de negatieve testen van Jack: Hetzelfde geldt voor ‘niet-functionele testen’ die heel functioneel (zinvol) zijn. En wat dacht je van regressietesten die voor veel progressie zorgen? Hebben wij als testers dat meer dan anderen, van die negatieve aanduidingen voor positieve dingen? Mmmm, geeft weer stof tot nadenken, leuk idee voor een volgende blog misschien ….
Egbert,
In je reactie (en artikel) laat je blijken dat er NIET altijd met geanonimiseerde data getest wordt. Bijvoorbeeld wanneer deze testset te klein is en er daarom – tegen alle regels in – op productie getest wordt. Dat bevreemd me nogal omdat ik ervan uitga dat actief bewaakt wordt wie, waarom en wanneer toegang verkrijgen tot persoons- en/of medische gegevens. Als ik dit zo lees wordt het EPD dus gewoon een testobject:(
@Henri
Ik schreef al in eerste reactie dat het allemaal een kwestie is van algebra, ook het aanmaken van fictieve Burger Service Nummers. Veel van dit soort nummers zijn namelijk gewoon gebaseerd op de elf- of negenproef. Met een beetje processorkracht, eventueel vanuit de cloud, genereer je zo een berg aan dit soort data:-)
Ik krijg dus nu het idee dat er teveel vanuit het antwoord gedacht wordt, wat is er mogelijk met de data die we hebben?