
Bovenstaande titel is misschien nogal cru, maar er zit natuurlijk wel een kern van waarheid in. In tegenstelling tot de ict-systemen(hardware) kan verloren data niet snel of eenvoudig vervangen worden. Om dit te voorkomen maken we daarom al jaren gebruik van back-up technologie. Dagelijks wordt de data veilig gesteld door middel van back-ups naar tape/disk, snapshot en replicatietechnologie.
Hierbij komt het nog te vaak voor dat er gekozen wordt voor een 'one size fits all'-oplossing. Dit soort oplossingen zijn, zoals we allemaal weten, niet het meest kosteneffectief. Ook sluit een dergelijke oplossing vaak niet aan bij de verschillende wensen en eisen binnen een organisatie. Tegenwoordig worden er namelijk vaak meerdere service-level agreements gehanteerd binnen een organisatie. Helaas komt men daar vaak pas achter als het al te laat is. Neem daarom van mij aan: voor back-up omgevingen geldt 'one size doesn't fit all'.
Door de enorme groei van bedrijfsdata is het vaak niet meer mogelijk om alle data op dezelfde manier en frequentie veilig te stellen. En zoals ik hier al vaker geroepen heb, is niet alles even bedrijfskritisch. De vakantiefoto's, gedownloade muziek en films van je medewerkers wil je natuurlijk niet veiligstellen en zeker niet langere tijd bewaren/archiveren. Het is daarom zaak om hier slim mee om te gaan. Hoe pak je dit aan? Waar moet je op letten, wat moet je wel en wat moet je juist niet doen?
Onderstaand enkele stappen die het proces kunnen versnellen:
Stap 1:
Neem de huidige back-up omgeving eens grondig onder de loep. Hoe vaak wordt er een back-up gemaakt? Hoe lang duurt dit eigenlijk? Wordt alles eigenlijk wel veilig gesteld? En tot slot: is de data die veilig gesteld is nog terug te zetten en weer opnieuw te gebruiken?
De uitkomst en antwoorden op bovenstaande vragen zullen velen verbazen. Het komt nog te vaak voor dat data verkeerd of nog erger helemaal niet veiliggesteld wordt. Of dat men werkelijk geen idee heeft of het terug te zetten en opnieuw te gebruiken is. Daarom is dit de perfecte stap om mee te beginnen. Maak eerst de pijn zichtbaar en kom dan met een gedegen oplossing.
Stap 2:
Maak eerst een scan van alle aanwezige data. Wat is er nu precies aan data aanwezig? Wie zijn de grootverbruikers? Waar bestaat mijn datalandschap uit? Waar komt de groei vandaan? Hoeveel dubbele data is er eigenlijk aanwezig? Etcetera. Zodra dit in kaart is gebracht kun je over gaan naar stap 3.
Stap 3:
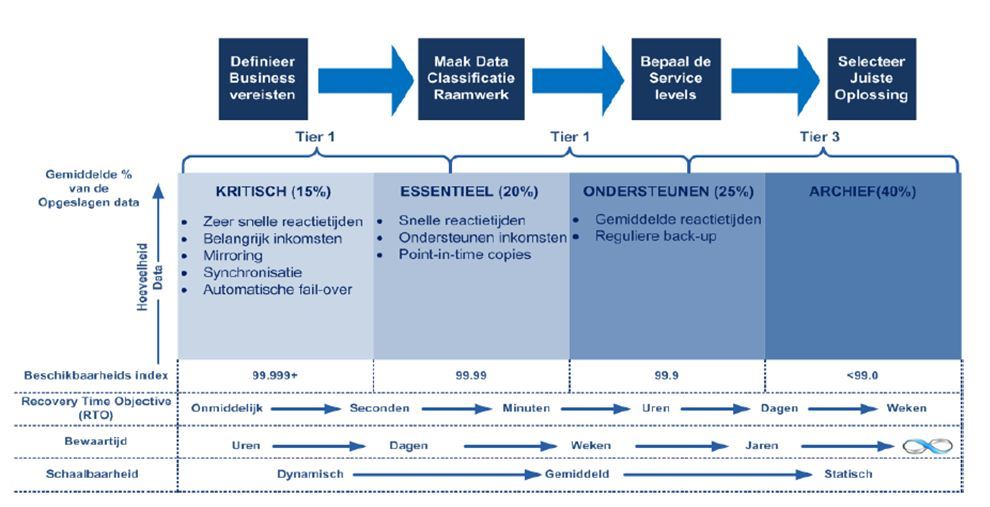
Stel een x aantal categorieën op waarin de data kan worden onderverdeeld. Breng per categorie een aantal randvoorwaarden aan, zoals:
– Hoe vaak dient de data veilig gesteld te worden?
– Moet de data überhaupt veilig gesteld worden?
– Wat is de RPO ( Recovery Point Objective )? Hoevele dataverlies kun je als organisatie aan?
– Wat is de RTO ( Recovery Time Objective ) van de data? Hoe snel dient de data in geval van een escalatie weer beschikbaar te zijn?
– Dient de data voor langere tijd gearchiveerd te worden?
Tijdens het definiëren van deze randvoorwaarden zult u er al snel achter komen dat niet alle data even bedrijfskritisch zijn, en niet alles in de categorie goud geplaatst hoeft te worden. Het is dan ook zeer gebruikelijk om per categorie een andere RPO/RTO op te stellen. Dit zal een zeer positief effect hebben op de kosten.
Stap 4:
Probeer de data onder te verdelen in de bovengenoemde categorieën. Probeer hierbij het aantal categorieën behapbaar te houden, zodat hier geen enorme wildgroei gaat onstaan. Te veel categorieën maakt het er nu eenmaal niet gemakkelijker op.
Stap 5:
Kijk naar de juiste technologie die bij de eerder gestelde wensen en eisen past. Het kan best zijn dat voor de catagorie 'goud' heel andere technologie nodig is dan voor de categorie 'zilver' op deze manier kunnen ook kosten bespaard worden op het gebied van hard- en software. Kijk goed naar de eerder gestelde randvoorwaarden en probeer deze naar de beschikbare technologieën te vertalen. Bij een RPO van vijftien minuten komt natuurlijk veel meer kijken dan als bij een RPO van 24 uur.
Voortgaand proces
Bovenstaande vijf stappen moeten in mijn optiek een voortgaand proces zijn. Op onze auto’s voeren we tenslotte ook meerdere keren per jaar onderhoud en eens per (twee) jaar apk-keuringen uit. Dus waarom niet op onze ict-omgevingen? Door de bovenstaande vijf stappen meerdere keren per jaar uit te voeren, kan een organisatie veel geld en nog erger, dataverlies besparen.









Dag Ruud, mooie praktische stappen. Het is maar waar je van houdt.
Vind de titel alleen helemaal op je verhaal aansluiten: Je schrijft niet over data, maar vooral over bestanden. Uiteindelijk is alle data wel te herleiden naar bestanden, maar je schrijft hier in mijn ogen over gewone gebruikers bestanden en back-ups en de stappen zijn niet goed toepasbaar op bijvoorbeeld databases. Of je moet de gehele database als 1 soort bestand zien in 1 categorie. Daarnaast verklaar je de titel ook niet echt.
Daarnaast klinken de stappen als een hoop werk, en in combinatie met “one size does not fit all” klinkt dat weer als maatwerk, en maatwerk is weer duur.
Daarnaast zijn er nog veel andere manieren om de beschikbaarheid van data veilig te stellen en hoewel je het soms abstract stel lees ik er toch een hoge “back-up” factor in.
Data die gestald is bij Google kan ook belangrijk zijn, maar daar gaan de traditionele manieren niet zomaar op.
Henri,
Allereerst bedankt voor je feedback.
Ik ben nu eenmaal iemand die graag over de praktijk schrijft wat ik tegen kom bij mijn klanten. Theorie is leuk maar in de praktijk gebeurd het echt.
Je hebt natuurlijk gelijk dat ik puur over het veiligstellen van bestanden schrijf. Maar bestanden zijn zoals je zelf al aangeeft te herleiden naar data.
En in dit stuk ben ik er vanuit gegaan dat een DB als 1 geheel gezien wordt. En natuurlijk doel ik op de backup van deze bestanden. Het apart backuppen van alle losse bestanden die een DB vormen is met het oog op inconsistentie ook niet aan te raden.
Ik deel niet je mening dat de bovengenoemde stappen een hoop werk in houden. Deze zijn in mijn ogen essentieel en leveren je uiteindelijk alleen maar profijt op. Als je geen goede classificatie op je data uitvoert ,weet je ook niet wat wel of niet belangrijk voor je is.
Niet alles dient in je backup mee genomen te worden, vandaar dat het definiëren van enkele categorieën ( met verschillende RPO/RTO) geen overbodige luxe is. Op deze manier kan je juist kosten besparen en zorg je er voor dat je RTO beter haalbaar wordt. Niet alles hoeft even snel weer beschikbaar te zijn na een escalatie. Dus vandaar mijn opmerking “One size doesn’t fit all”.
Data die op het internet of in de cloud staat, is natuurlijk een heel andere discussie. Daar ben ik niet specifiek op terug gekomen in mijn stuk. Maar ook hier voor moet een classificatie gedaan worden. Is het belang ja of nee? Dient het veiliggesteld te worden? En zo ja met welke frequentie? Als dat bekend is kan je daar over afspraken maken met de desbetreffende leverancier/aanbieder.
Bedankt Ruud voor je goede reactie. Ben vandaag ook niet op mijn best 😉 En je bent duidelijk in je betoog en ik geloof ook dat het belangrijk is. Virtuele servers moet je ook back-uppen en vergt weer een andere benadering. De ene virtuele server is de andere niet 🙂
Prive maak ik in feite ook onderscheid. Alles wat ik download voor consumptie (films, muziek, digitale boeken) zet ik op een schijf die gewoon kapot mag, de rest back-up ik via (cloud computing) tools en de allerbelangrijkste data versleutel ik eerst op een true crypt volume voordat ik die veilig bij Amazon stal.
Zo heb ik dus ook categorieën, maar de manier waarop ik back-up veranderd niet en zodoende is *alles* geautomatiseerd op dit vlak. In feite is de harde schijf van mijn thuis computer de back-up van wat ik in de cloud heb… da’s ook een interessante propositie….
Henri,
Zowel prive als zakelijk is het handig om categorieën te maken. Zo houdt je behapbaar. Doe je dat niet dan krijg je een wildgroei.
En veel bedrijven maken lokaal nog een kopie van van in de Cloud staat. Dus wat je schrijft is heel herkenbaar. Want als je om wat voor reden niet meer bij je data kan is zo’n backup erg handig.
Hoi Ruud,
Goed stukje en heel toevallig was ik vandaag bij een klant waar dit onderwerp op tafel kwam. Ik hamer dan op wat wil je eigenlijk of wil je wel dat je core systeem 4 uur uit de lucht is? Of 1 hele dag als je 1 x per dag een backup maakt. Dit moet je dan wel zien tegen de mogelijkheden. Als je 5 tb binnen 1 minuut weer terug wilt maak je een storage leverancier heel blij.
@Ruud
zonder IP connectie is er ook geen bedrijfsvoering meer mogelijk, om dat elke iCt-apparaat inmiddels aan een (IP) netwerk hangt en anders er binnenkort aan zal hangen. Misschien is de volgende link wat voor je: http://www.communicatie-infrastructuur.nl
@ Maarten,
Natuurlijk heb je helemaal gelijk. Er zijn natuurlijk nog tig van andere essentiële zaken te verzinnen.
Maar een IP netwerk , hardware en software waar zijn in zekere zin vervangbaar. Data creeer je zelf als bedrijf zijnde en als je dit kwijt raakt op wat voor manier ook, heb je een erg grote uitdaging. Want data bevat essentiële informatie over bijvoorbeeld je klanten. Wie heeft wat besteld en misschien nog wel belangrijker is het al betaald of niet? Data is hoe je het went of keert onvervangbaar.
Ondanks het verkapte manier van reclame maken is toch bedankt voor de link 🙂
Je site bevat zeker leerzame informatie,en het wordt ook nog eens op een begrijpelijke manier uitgelegd dat zelfs een leek zoals ik het begrijpt.
Goed verhaal, maar het is een traject gebaseerd op analyses en scans. Kan je niet van te voren een aantal uitgangspunten benoemen, eisen en wensen stellen en vervolgens zonder analyses categorieën vaststellen. Dan kom je misschien op een ander schema uit en een andere verdeling.
1. Stel vast welke data echt zeer kritisch is voor de bedrijfsvoering of de data die een asset vormt of data die je vanuit wetgeving moet bewaren. Dit is de categorie goud. Als er iets met deze dat gebeurt komt het kritieke bedrijfsproces stil te liggen of loopt je serieuze risico’s in termen van wetgeving of concurrentie positie.
Je kunt hier allerlei normen voor veiligstelling bedenken. Backup is er een, maar je kan ook denken aan 2 actieve kopieën of een back-up in de cloud.
2. Stel vervolgens vast welke andere data wordt gegenereerd en stel de waarde vast. Deze data is niet kritisch en kan waarschijnlijk na een korte tijd worden gearchiveerd. Denk aan e-mails, brieven, rapporten, etc.
3. Stel eisen en wensen op en ontwerp je data management omgeving en kijk niet alleen naar wat je nodig hebt maar ook naar de kosten.
Je zult zien dat je een andere discussie krijgt, maar ook dat je een meer toekomstgerichte structuur krijgt die beter aansluit op de bedrijfsvoering van morgen in plaats van “zo deden we het tot nu toe altijd”
Willem,
Allereerst bedankt voor je reactie. Zoals je al zegt staat en valt het bij je voorbereiding. Als je niet weet wat je hebt en niet weet hoe belangrijk het is, is dit essentieel om te doen.
Back-up kan natuurlijk op vele manieren lokaal, bij een hosting provider of in de Cloud. Het meest belangrijke is dat je RPO/RTO ook echt haalbaar blijven/zijn.
Dit blijft altijd een lastige en tijdrovende discussie. Maar uiteindelijk levert dit alleen maar profijt op en kan je op deze manier ook zeker kosten besparen.
Aanvullend bij stap 1 kan je ook opmerken dat als er niet regelmatig een recovery uitgevoerd wordt dit een aanwijzing is dat de recovery strategie niet betrouwbaar is. Immers de brandweer oefent ook regelmatig.
Dit is overigens eenvoudige te controleren door het aanspreekpunt hiervoor te vragen om een back-up terug te zetten. Als deze bleek wegtrekt dan weet je genoeg.