
Apache Lucene is een Java-bibliotheek voor geavanceerde zoekmachine-functionaliteiten. De technologie is geschikt voor vrijwel alle toepassingen waarbij de volledige tekst van documentcollecties doorzocht moet kunnen worden, in het bijzonder in cross-platformomgevingen. Het is een open-sourceproject dat gratis en vrij gedownload kan worden.
Geavanceerde functionaliteiten van Lucene omvatten parsing, indexering, phrase detection, verwijderen van stopwoorden, detectie van sleutelwoorden, de mogelijkheid om rekening te houden met de nabijheid van woorden, mogelijkheden om thesauri, phrase-lists en synoniemenlijsten in te zetten om problemen als synonymie (verschillende woorden of woordgroepen met eenzelfde betekenis) en polysemie (woorden of woordgroepen die verschillende betekenissen kunnen hebben) aan te pakken, enzovoorts. De resultaten van een indexering kunnen gebruikt worden om een documentcollectie te bekijken in een vector space model, dus als een document-by-term matrix: documenten zijn vectoren, de dimensies komen overeen met de voorkomende woorden in het vocabularium van de gehele tekstcollectie. Dit kan de basis vormen van tekstminingactiviteiten.
Lucene Server
Het grootste misverstand in verband met Apache Lucene is wel, dat het om een kant-en-klare zoekmachine zou gaan. Dat is niet zo. Lucene is een bibliotheek of API die gebruikt kan worden vanuit andere applicaties. Het is volledig in Java geschreven zodat het op elk willekeurig platform kan draaien. Veel gebruikers willen echter liever een 'native' (systeemeigen) versie hebben omdat dat performanter is. Daarom zijn er verschillende systeemvertalingen van Lucene gemaakt. Daardoor bestaat het nu naast Java bijvoorbeeld ook voor C++, voor PHP, Python, Ruby. Er is zelfs een .net-versie voor Windows-omgevingen. Je kunt Lucene beschouwen als een modulaire omgeving of blokkendoos. Allerlei voor zoekmotoren relevante software of front-ends kunnen aan Lucene toegevoegd worden. Apache heeft deze zelf, maar derden maken ook modules. Een bekende module voor Lucene is Apache Soir : dat is een complete zoekserver rond Lucene die kan graven in HTML- en XML-code en die API's voor JSON, Python en Ruby heeft ingebouwd. Mogelijkheden zijn onder andere markeren van zoekresultaten ('hit highlighting'), gefaceteerd zoeken, caching, replicatie, gedistributeerd zoeken, database-integratie, webbeheer en meerdere zoekinterfaces.
Zodra je Lucene in de originele Java-versie downloadt, zit alles erbij om meteen van start te gaan. Behalve de eigenlijke zoekmotorbibliotheek zit er namelijk ook een demo bij van een indexerings- en zoekapplicatie: alleen platte tekst en aan te roepen als Java-applets. Wij installeerden eerst Java op een Ubuntu Server 10.04.2 LTS 'Lucid Lynx'. Dat hoeft trouwens geen Sun Java te zijn: Ubuntu ondersteunt standaard OpenJDK en dat bleek prima te werken. Als je liever geen Java in een server wil installeren, zitten de Python- en de Perl-versies van Lucene in de standaard bibliotheken van Ubuntu. Het installeren van de Java-omgeving stelt niets voor: gewoon het archief uitpakken en dan de juiste JAR's opnemen in het Java ClassPath, zodat de juiste Java-classes aangeroepen kunnen worden. Hierbij kan verwezen worden naar de bijgevoegde democlasses om meteen gebruik te kunnen maken van Lucene. Dat start natuurlijk met het indexeren van beschikbare documentbestanden en kan met één opdrachtregel: java org.apache.lucene.demo.IndexFiles -docs /pad/naar/documenten.
Gebruikersinterface
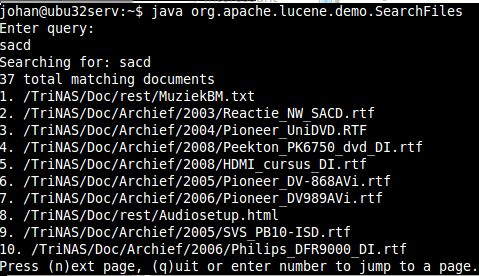
Aangezien Lucene een bibliotheek of op zijn zachtst gezegd een serverdienst is, is er eigenlijk geen gebruikersinterface aanwezig behalve de demotekstuele die er standaard bij zit. We zullen die dus voor deze test gebruiken, maar wijzen er wel uitdrukkelijk op dat er heel wat meer keuze is dan dat. Met behulp van de ruim beschikbare modules van Apache en derden kun je namelijk zelf kiezen wat voor gebruikersinterface je aan je gebruikers ter beschikking stelt. Doorgaans zal dat een webinterface zijn. De voornaamste reden waarom Lucene eerder als een zoekbibliotheek of -API beschouwd moet worden in plaats van als een volwaardige zoekmotor, is de ondersteuning van doorzoekbare documentbestanden. Die is er namelijk standaard niet: daarvoor heb je weer een afzonderlijke module nodig. Lucene ondersteunt standaard alleen platte ASCII-tekst, maar dat weerhoudt hem er niet van alle bestanden die je hem voorschotelt toch te doorzoeken. Documentformaten die platte tekst bevatten, zoals odf, rtf en de Microsoft 'Office Open xml'-formaten, kunnen op die manier dus toch probleemloos doorzocht worden. Niettemin is dit niet zaligmakend, want platte tekst die doorspekt is met font- en kleurinformatie vertroebelt immers het zoeken naar nuttige test en kan het zelfs onmogelijk maken. Documentbestanden die binair zijn kan hij zelfs helemaal niet doorzoeken (al probeert Lucene het wel). Daarvoor dienen modules die xml, html, pdf en alle mogelijke Microsoft Office- en odf-documenten ondersteunen: dan kunnen ze namelijk wel geïndexeerd worden en kunnen er resultaten getoond worden met behoud van de lay-out (fonts en kleuren). In de meegeleverde demo-Java-classes moet je het dus doen met platte tekst. Ook hier kan de zoekopdracht dan met één opdrachtregel: java org.apache.lucene.demo.SearchFiles.
De applet vraagt dan naar een zoekterm. Tik gewoon een woord en druk op enter. Dat levert veel resultaten op, gesorteerd in volgorde van hoe vaak het woord voorkomt en met een paginering om de tien resultaten met een optie om meer te zien.
Prestaties
Met deze democlasses hebben we even gemeten hoe snel Lucene eigenlijk is. Apache zelf geeft daar namelijk bijzonder indrukwekkende prestatiecijfers voor op. Meer dan 95 GB/uur indexeringssnelheid op moderne hardware terwijl er toch hooguit 1 MiB ram gebruikt wordt, bijvoorbeeld. Dat is dan wel zonder de Java-runtime die ook in het geheugen moet. Onze testboom werd volledig geïndexeerd in 28 minuten. Elke zoekopdracht die we daarna probeerden, kwam terug met een pagina zoekresultaten in minder dan één seconde. Inderdaad bijzonder snel.
Conclusie
De grote voordelen van Apache Lucene is dat het razendsnel is, open source en gratis. Het is echter geen klant-en-klare zoekmachine en er horen nog heel wat modules bij om het echt bruikbaar te maken voor een bedrijf. Maar juist omdat het modulair is, krijg je wel het maximum aan keuzevrijheid.
Productinfo
Product: Lucene 3.1
Producent & leverancier: Apache Software Foundation, USA; http://lucene.apache.org
Adviesprijs: gratis
Systeemvereisten: elk platform met Java
De Serie: Zoekmotoren en -servers
Deel 1: Xapian & Recoll levert verrassend goede zoekmachine op
Deel 2: TiNK Search
Deel 3: Apache Lucene
Deel 4: Xapian en Recoll









Lucene is ook beschikbaar als een .dll voor .net. Dus java is niet echt nodig op het platform. Uiteraard moet je er zelf een interface omheen bouwen.
We gebruiken het op onze site (een microsoft platform) en werkt erg goed, ook met spellingsuggesties bij typefouten in het zoekveld.