
Binnen de Rabobank zijn wij op dit moment bezig met het opzetten van beleid rondom architectuur. Dit is en blijft een continu proces. Het datawarehouse waar ik mij nu over buig, heeft twee functies.
De eerste is het verzorgen van managementinformatie voor de verschillende managementlagen van de afdeling (domein) waarvoor ik werk. De tweede functie is het verzorgen van de datalogistiek, domein overstijgend. Om die laatste functie te regelen zijn er verschillende mogelijkheden, die ik graag aan jullie wil voorleggen.
Laat ik eerst eens uitleggen wat ik bedoel met een domein. De bank kun je indelen in de volgende onderdelen die wij bij de Rabobank domeinen noemen.
Als eerste heb je een aantal productleveranciers, ook wel 'fabrieken' genoemd. Ik zal niet uitputtend zijn, maar je moet denken aan bijvoorbeeld:
1. Betalen
2. Sparen
3. Financieren
4. Effecten (aandelen, obligaties etc)
Deze domeinen ontwikkelen en verwerken de producten van de fabriek. Het zijn als het ware 'koekjes- fabrieken' die verschillende soorten koekjes maken. Het is aan andere afdelingen om deze in verschillende doosjes te doen en ze te verkopen. Naast deze 'fabrieken' hebben we dan ook marktgerichte afdelingen/domeinen zoals:
1. Particulieren
2. Private banking
3. Bedrijven/ Zakelijke markt
Deze afdelingen zorgen dat de juiste koekjes aan de juiste afnemers aangeboden kunnen worden. Niet elk koekje is geschikt voor elke koper.
Dan hebben we ook nog algemene afdelingen/domeinen zoals:
1. Control / Finance
2. Onderzoek
3. Marketing
En als laatste, het meest belangrijke domein: de aangesloten banken.
Zo heb je al heel snel elf domeinen. In werkelijkheid zijn het er ietsje meer.
Hoe verspreid je nu de informatie van de fabrieken naar de rest van de organisatie?
Binnen elke fabriek hebben we een datawarehouse. Ingericht met een staginglaag, datawarehouse en datamarts. Binnen elke fabriek kunnen wij de juiste management informatie leveren voor het management, de controllers etc van de fabriek. De bronsystement van de fabriek leveren ook hun gegevens aan het datawarehouse.
Elk ander domein heeft ook zijn eigen informatiebehoefte en -systemen om de gegevens van de verschillende fabrieken te verzamelen en te bewerken voor hun eigen doeleinden. Allemaal hebben ze behoefte aan een andere doorsnede van de gegevens vanuit de verschillende fabrieken.
In het verleden zijn er daardoor verschillende interfaces opgezet om deze gegevens vanuit de fabrieken te kunnen leveren. Soms ging dit via het datawarehouse van de fabriek en soms direct vanuit het bronsysteem. Veelal afhankelijk van persoonlijke contacten.
Nu zijn er de volgende mogelijkheden om informatie naar de andere domeinen te versturen:
1) vanuit de bronsystemen
2) vanuit het datawarehouse
3) vanuit een speciaal datalogistiek systeem
Als je alles vanuit het bronsysteem door de hele organisatie zou sturen, dan heeft dat als voordeel dat de lijnen kort zijn. Het is ook transparant waar de gegevens vandaan komen. Als nadeel kun je zeggen dat het bronsysteem een heleboel interfaces krijgt. De architectuur wordt een soort spaghetti en bij het testen van het bronsysteem zijn heel veel systemen betrokken. Het vervangen van een systeem kan door de interfaces ook moeizaam zijn. Je kunt er ook voor kiezen dat het bronsysteem maar één soort interface-bestand verstuurd en eenieder eruit mag halen wat hij nodig heeft.
Als je alles vanuit het datawarehouse verstuurt, dan heeft het als voordeel dat er één loket is, waar een ander domein kan aankloppen voor informatie. Je kunt dan ook gegevens versturen die uit meerdere bronsystemen komen in dat domein. Het aantal interfaces blijft beperkt. Het nadeel is dat er een schakel tussenkomt en dat het wellicht minder transparant wordt waar de data vandaan komen.
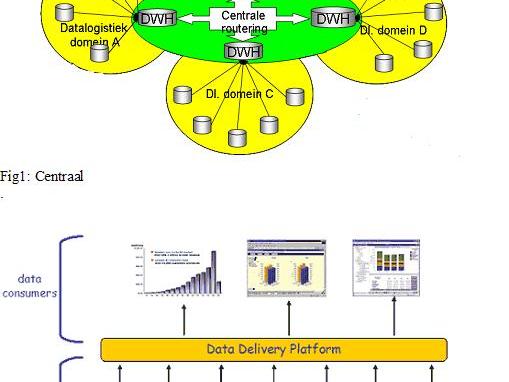
Je kunt ook denken aan een speciaal datalogistiek systeem. Je zou bijvoorbeeld aan een soort van centrale distributie kunnen denken. Ook hierin zijn er verschillende mogelijkheden. Je kunt dit doen door de verschillende datawarehouses files te leveren aan alle andere domeinen. Dit kan maatwerk zijn of een algemene file waar je uithaalt wat je nodig hebt. Je kunt dit doen met een Centraal datawarehouse, die de gegevens verzameld en opslaat van alle fabrieken. En zo ook weer de bron kan zijn voor alle informatie vragen (zie bijgaande figuur).
Of middelware waar iedereen zijn algemene file opzet en je kunt er af halen wat je nodig hebt.
Of moet kun denken aan een Data Delivery Platform van Rick van der Lans, waarin je de rapportages centraal stelt en verder de vragers van informatie loskoppeld van de leveranciers/fabrieken.
Meerdere opties zijn nog steeds mogelijk. Ook een combinatie van opties is mogelijk. Wij zijn er nog niet uit. Hierdoor ben ik ook erg benieuwd hoe andere bedrijven dit oplossen. Wat gebruik je in welke situatie en wat zijn jullie ervaringen?









Deze keuzes zijn in een greenfield situatie al lastig, maar in de praktijk heb je meestal te maken met een installed base (waarin meetal al veel geld is geïnvesteerd).
De ideale oplossing is een data landschap waarin de data (als in een warehouse) eenduidig conform open standaarden wordt opgeslagen. Daar omheen zou dan een repository met (eenduidig gedefinieerde) business logica beschikbaar moeten zijn. Hieruit zouden dan op basis van standaard beschikbare procedures de informatievoorziening van de verschillende bedrijfsprocessen moeten worden opgebouwd. Zolang deze situatie door schaalgrote, installed base of onvolkomenheid van het bedrijfsproces nog niet gerealiseerd kan worden, moet er gezorgd worden dat de beschikbare informatie middels eenduidig gedefinieerde koppelvlakken (op basis van open standaarden), kan worden afgebeeld op de centrale warehouse. De gebruikte businessapplicaties moeten als geheel in de repository met businesslogica worden opgenomen. Hoewel de applicatie dan als een black box opereert, zal de input, output en de bewerking die de informatie in de applicatie ondergaat eenduidig moeten zijn vastgelegd. Daar waar informatie niet eenduidig is af te beelden, de businesslogica van de verschillende applicaties strijdig is, of de bedrijfsprocessen dit niet kunnen ondersteunen, zal de informatie architectuur als eerst moeten worden aangepakt.
Mijn advies, niet de data verspreiden maar de data benaderbaar maken.
Zelf heb ik nog maar 1 best practise (ontwerp principe) overgehouden : bij complexiteit altijd investeren in een ontwerp die de complexiteit zo laag mogelijk houdt. Het ontwerp met de minste complexiteit wint het altijd op lange termijn. In deze casus zou ik de betekenis van informatie op 1 laag zetten d.m.v. dataservices en proberen de betekenis van data uit systemen te halen en deze alleen via dataservices naar buiten te brengen, geformaliseerd dus ! Dat is dan de enige waarheid van betekenis van informatie die gebruikt ‘mag’ worden, om informatie uit te wisselen. Zo worden applicaties minder belangrijk en wordt (nog belangrijker!) complexiteit (lees risico) van het applicatielandschap duidelijk. Of je dit nu realiseerd door een service bus architectuur of anders, is voor het logisch model minder van belang. Succes ermee !
Vanuit non functioneel (quality attributes) perspectief:
Altijd vanuit de authentieke bron, als actualiteit het belangrijkst is. Als snelheid het belangrijkst is (bijvoorbeeld veel batch data transport) valt een datalogistiek systeem te overwegen. Als consistente rapportage het belangrijkst is: vanuit het datawarehouse.
Hoi mede-expert,
het verhaal wordt nog complexer als je gaat proberen de veranderende databehoefte over tijd mee te nemen in je architectuur beslissingen (iets wat je helaas wel moet doen). Want wat je moet voorkomen is dat de innovatie van de systemen tot stilstand komt omdat wijzigingen in de data huishouding niet mogen worden doorgevoerd omdat dit teveel impact zou hebben om de omringende systemen. Om dit te voorkomen zul je naar een zogenaamd federated model toemoeten, iedereen verantwoordelijk voor zijn eigen datahuishouding, maar je stelt regels op en je richt een infrastructuur (waarin ook autorisatie en authenticatie is geregeld ed) zodat gecontroleerd data uitwisseling kan plaats vinden (en waarbij rekening wordt gehouden met wijzigingen in datadefinities door de tijd heen). Mocht je verder van gedachten wisselen, stuur me een directe mail, dan neem ik contact op.
Succes.