
Bent je ook zo vaak op zoek naar informatie of gegevens? Waar heb ik het gelaten, welke collega zou me hierbij kunnen helpen, heb ik wel de laatste versie en kloppen deze cijfers wel met de berichten die ik over dit onderwerp lees? Allemaal vragen die in veel organisaties leiden tot het zoeken naar informatie en veel tijdverlies. Ook productiviteitsverlies bij ondersteunende afdelingen speelt een rol. Decision makers nemen een besluit op basis van onvolledige informatie.
Terwijl ongestructureerde informatie in de vorm van teksten te vinden is in directory structuren en document management oplossingen (enterprise content management) en 80 procent beslaat, nemen managers in veel gevallen besluiten op basis van rapporten die voortkomen uit de gestructureerde data die slechts 20 procent in omvang beslaat.
Maar wat als die 20 procent je onvoldoende houvast geeft, als je beide typen informatiestromen nodig hebt en liefst gecombineerd, eenvoudig en snel? Welke mogelijkheden en nieuwe ontwikkelingen zijn er te verwachten vanuit de markt van de enterprise search oplossingen die dit vraagstuk voor de manager slechten? Is het al (bijna) zover of is het nog een brug te ver? In dit artikel gaan we op zoek naar een antwoord op deze vragen.
Theorie eim
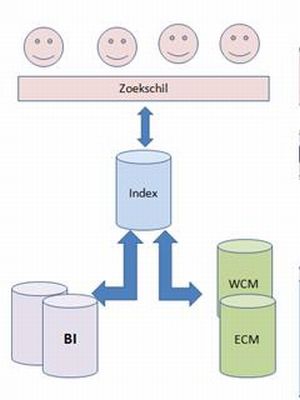
In de theorie rondom enterprise information management (eim) komt zowel gestructureerde informatie als ongestructureerde informatie samen. Dat wil zeggen dat beide informatiestromen gecombineerd gepresenteerd worden. Data (bi) gecombineerd met informatie (ecm) levert snellere en betere besluitvorming.
Een integrale oplossing binnen de eim gedachte gaat uit van het opslaan van content en data, in één index, zodanig dat met een zoekoplossing (esr) resultaten verkregen worden. In het artikel 'Enterprise search is randvoorwaarde voor eim' van Computable-expert Paul Baan werd al benadrukt dat de integratie van business intelligence (bi) en enterprise content management (ecm) plaatsvindt via enterprise search: met behulp van een zoekmachine worden data en content samengebracht in een portal.
Is het al zover dat dit kan? De eerste producten komen nu op de markt waarmee eim werkelijkheid wordt. Wat is hiervoor nodig? Het belangrijkste is een gezamenlijk referentiekader. Dit kan worden ingevuld met metadata. Metadata is de Haarlemmer olie van de oplossing. Echter metadata heeft in gestructureerde omgevingen vaak een andere betekenis dan in omgevingen waar ongestructureerde data wordt vastgelegd. Hierin moet dus ook een goede afstemming in de organisatie plaatsvinden zodat de metadata op een eenduidige manier kan zorgen voor de koppeling tussen beide informatiestromen.
Goede indexen
Gebruiken de databaserecords en de ongestructureerde documenten dezelfde termen? Met andere woorden komen relevante resultaten terug uit beide stromen als je op een term zoekt? Soms wel, maar meestal niet. Dit betekent dat veel aandacht besteed moet worden aan kwalitatief goede indexen waarbij synoniemen, gerelateerde termen en concepten aanwezig zijn.
Metadata moet op elkaar zijn afgestemd om de juiste informatie aan elkaar te kunnen relateren.Op basis van deze metadata kan men de informatie opleveren die bij elkaar hoort. Omdat alles in één index is gecentraliseerd, komt met één bevraging alle informatie beschikbaar. Het is niet meer relevant waar de gegevens vandaan komen. Hiermee creëer je dan een universele index of te wel unified information access (uia).
Processtappen
De grote vraag blijft echter: Hoe vullen we nu de index zodanig dat de zoekschil van hieruit antwoorden kan genereren op onze vragen? Het komt er op neer dat de inhoud van de database wordt ingelezen (inclusief de metadata en de relaties tussen de elementen en dat daar de resultaten van de tekstanalyse vanuit ecm en wcm aan worden toegevoegd.
Deze twee processtappen zijn onafhankelijk van elkaar. Als men dan zoekt naar 'Janssen' dan zijn er een aantal documenten waarin de naam voorkomt en komt de naam ook voor in de database. Op basis van de verwijzende sleutels die in de database gedefinieerd zijn (en die zijn overgenomen in de index) kan de bij 'Janssen' behorende detailinformatie worden opgehaald. Dit geldt zowel voor de transactionele als de dimensionele gegevens van 'Janssen'.
Doordat de informatie in het tool op eenzelfde manier wordt opgebouwd ongeacht de herkomst (gestructureerd dan wel ongestructureerd) kan deze worden gecombineerd en geïntegreerd op de manier waarop de gebruiker dat op een willekeurig moment wil. Met andere woorden: 'Ladies and Gentlemen, we have the technology, we can and must rebuild the information environment'.
Bottleneck
Wat wordt dan de bottleneck voor de implementatie? Omdat metadata zo'n prominente rol in de oplossing heeft is het afstemmen van deze informatielaag door de totale organisatie wellicht een cruciaal onderdeel. Metadata management wordt noodzakelijk. Hiermee kan worden bereikt dat iedereen met dezelfde metadata zijn informatie samenstelt. Net als bij gewone data betekent dit dat er kwaliteitsaspecten moeten worden onderkend, dat het centraal beschikbaar moet zijn, et cetera.
Een andere uitdaging is de autorisatie van de betreffende informatie. Wie mag welke informatie onder welke condities zien? Autorisatie is van groot belang voor de acceptatie van de zoekapplicatie door de gebruikers (niemand wil gevoelige informatie delen met onbevoegden). Daarbij speelt de snelheid waarmee de resultaten gevonden en gepresenteerd kunnen worden een grote rol.
Een document dat is weggeschreven met beperkte rechten moet door de zoekmachine als zodanig worden gerespecteerd, dat wil zeggen de rechten moeten worden 'overerfd' en in de index bij het document worden opgeslagen. Hiermee hebben we ongetwijfeld niet alle aandachtspunten onder de loep genomen, maar wel een beeld geschetst van hetgeen men waarschijnlijk tegen zal komen.
Conclusie
Een brug te ver? Nee dus! Het samenbrengen van ongestructureerde en gestructureerde informatie in een gezamenlijk toegankelijke index met gecombineerde resultaten is al wel degelijk mogelijk. Het wordt tijd onder de randvoorwaarden van zorgvuldige implementatietrajecten hiermee te gaan werken. De voordelen zullen niet lang op zich laten wachten.
Anja van der Lans MKM en Peter van Til, business consultants bij VLC
Over de auteurs
Anja van der Lans MKM publiceert regelmatig over ecm en is business consultant enterprise search and retrieval (esr). Peter van Til is business consultant business intelligence en auteur van het boek 'Business Intelligence, de eenduidige informatieomgeving en de gevolgen voor de business'. Dit artikel is een samenvatting van een groter artikel dat te vinden is op de website van VLC.




Naar mijn mening gaan de schrijvers voorbij aan het feit dat veel van de ongestructureerde data gebaseerd is op de gestructureerde data. Denk bijvoorbeeld aan productbeschrijvingen, jaarverslagen, etc. Als een decision maker een beslissing neemt op basis van de 20% gestructureerde data, is die beslissing dus ook indirect op een gedeelte van de ongestructureerde data.
Daarnaast ben ik er niet van overtuigd dat gestructureerde data in een index thuishoort. Ik denk dat de gestructureerde data met behulp van business rules uit de datastore gehaald moet worden en door de decision makers moet worden geïnterpreteerd.
O ja, in de eerste zin “Bent je ook zo vaak op zoek naar informatie of gegevens?” mag de “t” achter ben weg.
Ik ben er niet van overtuigd dat de oplossing van de problemen gezocht moeten worden in het herbouwen van het informatie systeem. Het is waar dat metadata een belangrijke rol speelt met het beschikbaar krijgen van informatie. Het vastleggen van informatiestructuren door goede afspraken te maken binnen een organisatie wordt hier wel heel simpel voorgesteld. Naar mijn ervaring zijn organisaties daar in de meeste gevallen niet toe in staat. Vooraf bestaat eenvoudigweg ook het inzicht nog niet in wat de informatie voor de verschillende gebruikers in een organisatie zal gaan betekenen.
De laatste generatie Enterprise Search Platformen zijn sterk verbeterd. Ook het gebruik van metadata door een enterprise heen maakt onderdeel uit van deze verbeteringen. Daar mee is het zeker beter mogelijk om die basis structuur op te bouwen en uit te bouwen. Bijvoorbeeld door een hierarchie van begrippen te definieren en deze sets door de gehele enterprise beschikbaar te stellen.
Veel belangrijker is de wijze waarop de medewerkers vervolgens geholpen worden om juist gebruik te maken van deze basis structuren. Het platform moet de keuze bij het creeren van de informatie faciliteren.
Een systeem wat enkel voorziet in de vooraf bedachte informatie structuur en daarbij zelfs nog in staat is om het juiste advies over het gebruik daarvan te faciliteren, kan rekenen op veel onderhoud van informatie specialisten.
Organisaties zijn zoals de naam eigenlijk al aangeeft niet statisch. Datzelfde geldt voor de informatiebehoefte. De systemen en platformen die deze ondersteunen moeten (en bieden steeds vaker) de mogelijkheid hebben om deze wijzigingen in inzicht te absorberen en implementeren. Kennis zit in de mens die de informatie interpreteerd. Deze zijn de enige die de kwaliteit echt kunnen beoordelen.
Binnen de laatste generatie platformen zie je dit besef ook steeds vaker in technologie en functionaliteit terugkeren. Neem de mogelijkheid die je zoals in deze blog hebt om een reactie te plaatsen en ratings aan te brengen. Met andere woorden de gebruiker bepaald voor een belangrijk deel de gepercipieerde kwaliteit van de informatie. Hoe nuttig was deze info voor mij toen ik deze gebruikte om mijn informatie behoefte te vervullen.
De ontwikkeling van deze technologieen zullen een veel grotere impact hebben op het vinden en gebruiken van informatie als de digitale vertaling van de kaartindex van voorheen.