
Het menselijk brein weet dat het euroteken voor een getal vijf in een catalogus betekent dat het ding ernaast vijf euro kost. U en ik weten ook perfect hoe we op het web de goedkoopste dvd kunnen vinden. Computers weten niet eens waar het over gaat. Het semantisch web kan daar verandering in brengen.
Voor eindgebruikers kan het semantisch web voor dagelijkse dingen een soort expertsysteem worden. Je wilt een afspraak met de kapper op een vrije dag? Het semantisch web zal daar ooit voor kunnen zorgen. Voor het zover is moeten leveranciers als Oracle, IBM, Adobe, Discovery Machine en vele anderen nog hard aan de weg timmeren. In zijn ruwe vorm is de technologie er al, maar zijn er ook al producten?
Welbepaalde structuur
Wat het semantisch web zal kunnen, kan in sommige gevallen nu ook al. Het semantisch web is echter wel zo handig, omdat het gebaseerd is op open standaarden en de brug slaat tussen menselijk en machinaal denken. Het semantisch web, een geesteskind van ‘www-uitvinder’ Tim Berners-Lee, is ontwikkeld als aanvulling op het huidige web. Berners-Lee ontwierp het met zijn team om de betekenis van stukjes informatie een welbepaalde structuur te geven, waardoor machines ermee aan de slag kunnen in een voor mensen zinvolle context.
Binnen een semantisch kader kunnen we bijvoorbeeld gegevens definiëren en onderling verbinden op zo’n manier dat ze inzetbaar zijn voor een effectieve ontdekking van kennis, de automatisering daarvan en de integratie met van elkaar verschillende toepassingen. Daarnaast moeten de gegevens zelf herbruikbaar zijn over verschillende toepassingen heen. Vooral hier wringt de schoen: informatie uit een erp-systeem is niet noodzakelijk op dezelfde manier gestructureerd als databasegegevens. Het semantisch web overbrugt de verschillen door betekenissen die voor mensen zinnig zijn ook voor machines ‘zinvol’ te maken.
Er zijn diverse toepassingen die van de technieken van het semantisch web gulzig gebruik maken. Een tot de verbeelding sprekend voorbeeld is Adobe’s xmp (extensible metadata platform). In alle Adobe-producten opent de gebruiker na het selecteren van de menukeuze ‘document eigenschappen’ een venster waarin allerlei metadata over een bestand is terug te vinden. Voor digitale foto’s kan dat exif-informatie (exchangeable image file format) zijn die de camera aan de foto heeft gekoppeld, maar het venster bevat veel meer. Ook auteursrechtelijke gegevens, adressen en zelfs instructies voor de ontvanger kunnen in verschillende panelen worden ingevuld.
Ontologie
Semantisch wordt xmp pas echt doordat het gebruik maakt van XML en rdf (resource description framework), en de machine de data kan gebruiken om een automatische werkstroom te organiseren. In drukkerijen resulteert dat in het gebruik van xmp-data om de drukpers te voorzien van de correcte instellingen wat betreft kleuren, resolutie enzovoort. Adobe levert een softwareontwikkeltoolkit waarmee de xmp-gegevens ook kunnen dienen om een jdf-werkstroom (job description format) te organiseren. De programmeur vertaalt de beschrijvende xmp-gegevens dan naar de voorschrijvende jdf-data. Jdf is de schakel tussen de werkstroom op de werkvloer in een drukkerij en de administratieve afdeling.
IBM werkt ook aan het semantisch web. Het concern richt zich daartoe op ontwikkelwerktuigen waarmee organisaties zelf systemen kunnen uitbouwen voor bijvoorbeeld webgebaseerde services. Het concern levert vooral instrumenten voor handmatige creatie en ontologie (eigenschappenleer) en werktuigen om toegang daartoe te verschaffen via zoeken en bladeren door zowel mensen als toepassingen. Daarnaast levert het tools om automatisch eigenschappen te creëren uit documenten, om multimedia, foto’s en dergelijke te verrijken met metadata door deze te voorzien van labels.
IBM is ook betrokken bij het ontwikkelen van de standaarden die nodig zijn om dat alles in een gedistribueerde omgeving te kunnen gebruiken, wat een stap verder is dan gewone webservices: semantische webdiensten. Vooral in het domein van het onttrekken van eigenschappen aan documenten begeeft IBM zich in het vaarwater van wat vroeger kunstmatige intelligentie heette. Het semantisch web heeft dan ook raakvlakken met natuurlijke taalanalyse en -generatie. IBM’s ai-werktuig (artificial intelligence) heet ABLE (Agent Building and Learning Environment).
Het concern legt de nadruk wat betreft praktische toepassingen voorlopig vooral op soa (service-oriented architecture). Webservices zijn ‘intelligent’ en efficiënt te maken via semantischwebtechnologie. Daarnaast ziet IBM nu al toepassingen in de farmaceutische industrie, waar dankzij die technologie onderzoekers razendsnel de verbanden tussen moleculen en hun werking kunnen zien in een simpele browser.
Beslissingsbomen
Een kleine leverancier die in Europa slechts marginaal aanwezig is, Discovery Machine, gebruikt semantischwebtechnologie om trainingen te leveren aan de Amerikaanse marine. Dit bedrijf maakt geen gebruik van kunstmatige intelligentie, maar wel van eigenschappen en een zelf ontwikkeld systeem dat net als IBM’s ABLE leert – in dit geval van wat de gebruiker in het systeem invoert als antwoord op vragen.
Ook Oracle werk aan het semantisch web. De database ondersteunt SPARQL/rdf, XQuery/XML en SQL/rdbms. Verder herkent de database beslissingsbomen. Ondersteuning voor OWL (Web Ontology Language) is er nog niet, maar voor de nabije toekomst wel gepland. Oracles Han Wammes, market development manager Spatial Information Management, zegt dat zijn eigen specialisme, gis’en (geografisch informatie systeem), terugkomt in bepaalde concepten voor de ondersteuning van het semantisch web van zijn bedrijf. Het ‘netwerk data model’ bijvoorbeeld is in eerste instantie ontwikkeld voor routering, maar ook geschikt voor beslissingsbomen.
Wammes wijst op toepassingen die partners nu al ontwikkelen. Het Amerikaanse Cerebra bijvoorbeeld concentreert zich net als IBM op soa, maar dan met Oracles 10g Release 2 databasetechnologie als fundament. In Nederland ziet Wammes toepassingen van het semantisch web voorlopig vooral nog in de academische sfeer, en ‘life sciences’ zijn er volgens hem druk mee bezig. “Verder is er grote belangstelling vanuit overheidshoek”, aldus Wammes. “Organisaties als het ministerie van Landbouw en het Kadaster tonen belangstelling omdat de met het semantisch web geassocieerde technieken de informatie kunnen helpen ontsluiten over het web, naar eindgebruikers toe.”
Dat ook de defensie-industrie grote belangstelling heeft, is niet verbazingwekkend. Ook de Europese Commissie blijft niet achter: in juni sponsort ESSI (EU 6th framework programma) de derde Annual European Semantic Web Conference in Budva (Montenegro). Daar komen de jongste resultaten op het vlak van onderzoek en toepassingen aan de orde. Deelnemers kunnen ook cursussen volgen om meer te leren over de laatste semantischwebtechnieken.[Erik vlietinck
Tim Berners-Lee
Tim Berners-Lee stelde in 1980 als consulent voor CERN een project voor dat het idee van hypertext bevatte. Met Robert Cailliau bouwde hij zijn eerste prototype, ENQUIRE. Toen al wilden de heren semantische functionaliteit. Om praktische redenen kwam dat er niet van. In 1984 werd Berners-Lee CERN-fellow. In 1989 is de eerste webserver ontwikkeld op NeXTSTEP. Drie jaar later was de eerste website, die van CERN, gerealiseerd. Weer drie jaar later richtte Berners-Lee W3C (World Wide Web Consortium) op in de schoot van MIT (Massachussets Institute of Technology). In 2000 drongen webbrowsers door tot het grote publiek. Eind 2004 kreeg Berners-Lee een leerstoel aan de University of Southampton. In die hoedanigheid zei hij eind 2005 in een lezing over het semantisch web: “Ik wilde een web dat vooral samenwerking zou bevorderen.” Hij is dan ook erg te spreken over wiki’s en blogs. Het semantisch web gaat wel een forse stap verder.
Lagenmodel
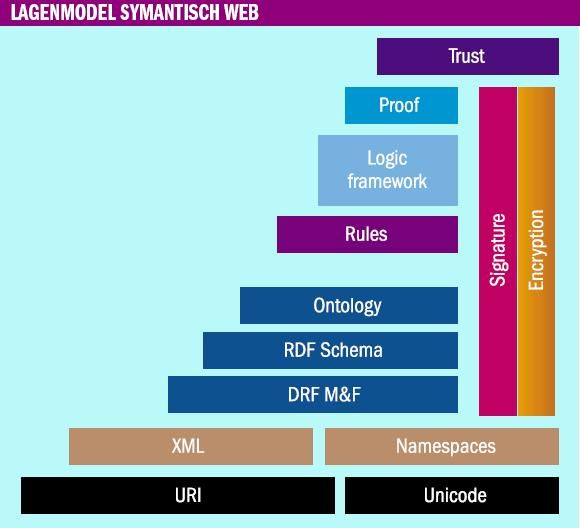
Op technologisch niveau leiden de concepten voor het semantisch web tot een lagenmodel waarvan de werking vergelijkbaar is aan wat bloggers met http (hyper text transport protocol) en HTML (Hyper Text Markup Language) doen.
De basislaag gebruikt uri’s (uniform resource identifier) die urn’s (uniform resource name) omvatten waarmee concepten en dingen op een unieke wijze te identificeren zijn. Daarnaast zijn er binnen het domein van uri’s de url’s (uniform resource locator) om de dingen te lokaliseren. Deze laag is vrijwel identiek aan het http-systeem voor het lokaliseren van webpagina’s. Hoger in het model gebruikt het semantisch web XML (eXtensible Markup Language) en een XML-extensie voor ‘namespaces’ . In een namespace is een uri gemodelleerd als qName; een ‘qualifier’ die het gebruikte woordenboek en het element daarin waar het uri-element op slaat aanduidt. In het semantisch web kunnen verschillende, zelfs overlappende woordenboeken bestaan. Namespaces leveren de unieke identificatie voor elk item in elk woordenboek. De XML-laag is vergelijkbaar met HTML. De volgende laag is ‘rdf model & syntax’ (resource description framework). W3C beveelt deze datalaag aan. De rdf-datastructuur bestaat uit een triplet, waarin een onderwerp, een attribuut en een voorwerp zijn opgenomen. Het zegt iets over een stukje data, gebruikmakend van die structuur. RDF Schema is een taal die rdf-woordenboeken beschrijft. Met deze taal zijn klassen en eigenschappen in hiërarchieën te beschrijven, en het domein en het gamma aan eigenschappen te beperken. Ze zijn daarom belangrijk voor het deduceren van betekenis (inferencing). Een eenvoudige implementatie van deze laag komt overeen met wat bloggers rss (really simple syndication) noemen – een manier om inhoud naar de gebruiker toe te pushen in een nieuwslezertoepassing. De hoogste laag is de ontologie of semantische laag. W3C beveelt op dit niveau het gebruik van OWL (Web Ontology Language) aan. Ontologie is de leer van de algemene eigenschappen van dingen. OWL ondersteunt de uitwisseling tussen alle vormen van eigenschappen. Die zijn namelijk op verschillende manieren uit te bouwen: in een systeem van vakjes, gebaseerd op diagrammen met verbindingen, of gewoon door betekenissen te beschrijven. Met de ontologielaag zijn eigenschappen terug te brengen tot hun fundament. Op die manier is deze laag te gebruiken voor geavanceerdere betekenisdeductie dan met RDF Schema mogelijk is. De semantische laag zorgt dat machine en gebruiker het over hetzelfde onderwerp hebben. Iets vergelijkbaars is er niet in het gewone webmodel, afgezien van de ‘tags’ waarmee bloggers tegenwoordig hun inhoud labellen opdat websites als Technorati en De.licio.us gecategoriseerde lijsten kunnen maken.
Webbron
In het semantisch web speelt rdf een centrale rol. Door het concept van een webbron te introduceren is rdf te gebruiken om informatie weer te geven over dingen die op het web wel te identificeren zijn, maar niet rechtstreeks benaderd kunnen worden. Denk aan een toepassing in een soa (service oriented architecture). Rdf speelt dan de rol van tussenschakel die ervoor zorgt dat toepassingen de informatie kunnen verwerken zonder dat de betekenis ervan verloren gaat. Net als HTML kunnen machines rdf en XML verwerken, en zijn stukjes informatie van waar dan ook op het web aan elkaar te koppelen door uri’s. In tegenstelling tot HTML kunnen rdf uri’s verwijzen naar elk identificeerbaar ding of concept, en niet alleen naar dingen die direct van het web in een webbrowser binnen te halen zijn. Het enige wat op dit niveau nog nodig is, is een taal die de informatie uit rdf-diagrammen kan halen. Voor databases is er bijvoorbeeld SPARQL. Met SPARQL kan je zelfs nieuwe rdf-diagrammen vormen op basis van de informatie in ondervraagde diagrammen.








