
Het relatief trage systeemgeheugen is een rem op de snelle dualcore serverprocessoren van AMD en Intel. Een test van Computable wijst uit dat systemen beter overweg kunnen met rekenintensieve taken dan met applicaties die het geheugen veel aanspreken.
De ene dualcore-server is de andere niet, blijkt uit een test van Computable. Hierbij zijn twee machines, één met AMD dualcore-processoren en één met Intel dualcore-chips, met elkaar vergeleken. Eerstgenoemde heeft acht 2,4 GHz Opterons op een Tyan S4881-moederbord met M4881 cpu-bord van TCW (www.tcw.biz). De tweede machine is een IBM xSeries 460-systeem met daarin vier 3 GHz Paxville MP-processoren met HyperThreading. De Intel-processoren hebben door de multithreading-technologie HyperThreading een dubbel aantal virtuele processoren per kern. De AMD Opteron heeft geen HyperThreading of een tegenhanger daarvoor, zodat een dualcore chip dus twee virtuele processoren oplevert. In het Taakbeheer-venster van Windows zijn bij AMD vier en bij Intel acht virtuele processoren te zien. Servers met vier sockets tonen met AMD-chips acht en met Intel-processoren maar liefst zestien virtuele cpu’s.
Knelpunt
Een potentieel knelpunt bij dualcore of multicore is het snelle oplopen van de werkdruk op de infrastructuur (chipset, bus en geheugen) rond de processor. Weinig spraakzame programmatuur zoals rekenintensieve software levert hier de minste problemen op. Toepassingen als beeldbewerking, transformatie en simulatie draaien goed op de geteste hardware, aangezien deze software grotendeels in de snelle cache van elke processor blijft. Het prestatieniveau van de server hangt bij Paxville- en Opteron-chips sterk af van het aantal intensief werkende werktaken. Zijn er wel genoeg daarvan binnen een enkel programma of voortvloeiend uit een aantal processen? Een te laag aantal zware werktaken laat de processorhardware letterlijk onbenut.
Reguliere applicaties communiceren juist intensief met het geheugen en belasten de hardware rond de processor dus meer dan rekenintensieve applicaties. Dit kan de druk op de omgeving van AMD’s processor verdubbelen (acht dualcore chips) en die op de omgeving van Intels processor verviervoudigen (vier dualcore chips met HyperThreading). Dit is geen nieuw fenomeen bij servers met meerdere sockets (SMP), die al jaren op de markt zijn. De werklast loopt echter zeer snel op als het geheugen veel wordt aangesproken door de kernen in een enkele processor en de meerdere processoren in één serversysteem.
Dit effect wordt versterkt doordat de huidige dualcore chips van Intel en AMD nog relatief grof en eenvoudig van opzet zijn. In de huidige Paxville-generatie worden twee losse silicium chips samengevoegd in één processorbehuizing. Het is daarmee een mechanische en relatief dure vorm van dualcore.
Structuur Paxville versus Opteron
Intel gebruikt voor deze eerste generatie dualcore processoren een enkel hoofdgeheugen. Elke processor in een systeem moet dit hoofdgeheugen delen met de andere processoren. Voordeel voor Intel is wel dat het bedrijf dit ontwerp vrij snel op de markt kon brengen.
Concurrent AMD heeft met de Opteron een dualcore serverprocessor die bestaat uit twee kernen zij-aan-zij op één stuk silicium, in een relatief traditionele processorbehuizing. Het ontwerp is symmetrisch, de twee processoren werken op het ene plakje silicium functioneel gezien gescheiden naast elkaar. De fabrikant heeft hierbij een geheel andere architectuur dan concurrent Intel voor de verbinding met het hoofdgeheugen. Voor elke Opteron kan eigen geheugen worden geplaatst. Multiprocessor-systemen hebben een snelle interconnect tussen de verschillende processoren, de zogenoemde HyperTransport-bus.
De hogere werkdruk op de omgeving rond de processor valt ongelukkigerwijs samen met een andere ontwikkeling van de laatste jaren: het flinke achterblijven van de geheugensnelheid bij de snelheidstoename van processoren. Bij Pentium-III processoren was de verhouding tussen processor en geheugen (bus/core-ratio) een factor vier, bij huidige processoren is dat al bijna een factor tien. Indien de bus/core-ratio hoog is, neemt de kans op prestatieproblemen toe voor toepassingen die het geheugen intensief gebruiken. Dit kan dodelijk zijn voor de prestatiesprong van dual- en multicore-processoren.
Bij grote verschillen tussen het prestatieniveau van de core en de busverbinding naar het geheugen springt het cachegeheugen bij. Dit zit dan tussen core en bus om de snelheidsverschillen op te vangen door vaak gebruikte geheugenlocaties paraat te houden.
Cache-omvang
De cache kan eerder gebruikte gegevens direct aan de kernen leveren, wat de werkdruk in de processoromgeving verlaagt. De processor spreekt de bus alleen aan als niet eerder geraadpleegde gegevens nodig zijn die niet in de cache aanwezig zijn. Intel gaat dit in dualcore-systemen te lijf met een grotere cache. Dat stelt het gebruik van de bus naar het hoofdgeheugen uit en geeft dus meer ruimte aan andere processoren (die ook van het hoofdgeheugen afhankelijk zijn.
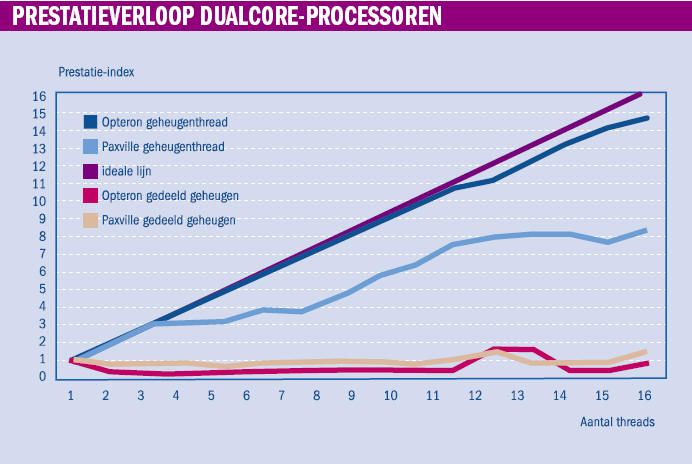
Een eenvoudige test spreekt op het AMD- en Intel-systeem de zestien cores aan door een doorvoercijfer te geven aan iedere thread (een soort mini-proces) die in de buffer is ingelezen. Daarbij ontstaat een cijferreeks wanneer een nieuwe thread wordt gestart. De piekbelasting van de servers is bereikt als het totale aantal virtuele processoren (zestien) in de machines aan het werk is. De systemen beginnen met 1,2 (AMD) en 1,4 (Intel) Gbps bij één thread. Het energieverbruik van de systemen ligt dan rond de 200 Watt. AMD levert bij volledige belasting een ontzagwekkende 20 GB per seconde op, maar verbruikt dan wel 800 Watt. Intel blijft achter met slechts 11 GB per seconde en heeft dan een energieverbruik van ruim 500 Watt.
De inhoud van de buffer is hierbij kleiner gehouden dan de omvang van de cache. De test geeft daarmee een indicatie van het prestatieverloop als een applicatie genoeg heeft aan de geheugenruimte in de cache. Dezelfde test op een server met acht Opteron-processoren laat een beter beeld zien: de prestaties blijven toenemen. Ook als de laatste thread wordt opgestart, nemen de prestaties van het systeem met één zestiende toe.
Voor rekenintensieve taken presteert zowel het Intel- als het AMD-systeem tot op zekere hoogte lineair; er is geen verzadigingspunt. Opvallend genoeg presteert de Opteron in de rekentest meer dan twintig procent beter, ondanks de lagere kloksnelheid (2.4 GHz versus 3 GHz). De prestaties van de Paxville nemen boven de acht testtaken niet meer lineair toe. De prestaties van dit systeem vlakken vanaf dat moment juist af. Het door Intel ontwikkelde HyperThreading heeft bij deze werklast geen positieve invloed op het systeem. Kennelijk speelt het delen van het geheugen door de cores hier een rol.
Geheugenintensieve test
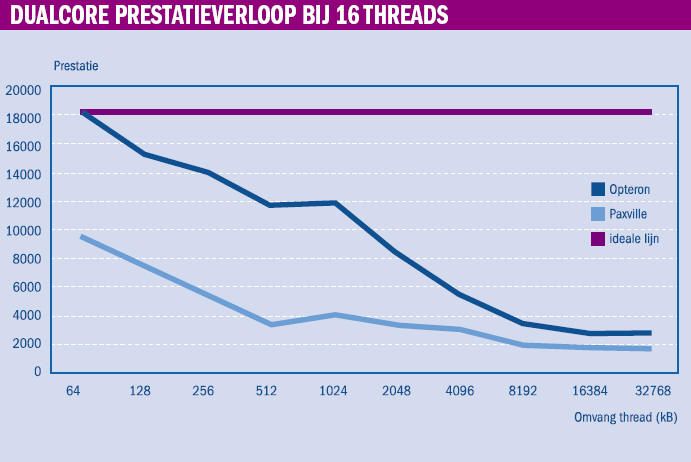
In een tweede test is de inhoud van de buffer groter gemaakt dan de omvang van de cache. Verder is willekeur toegepast voor het lezen van geheugenposities. Deze aanpak geeft een weerslag van het prestatieverloop als de kernen en het hoofdgeheugen veel informatie moeten uitwisselen. Door de grotere data-omvang en de willekeur ervan kan de cache niet meer als buffer fungeren tussen de kernen en de bus. Deze belasting is vergelijkbaar met het functioneren van één zeer grote applicatie of van een aantal wisselende taken. Dit heeft een te verwachten invloed op het prestatieniveau van de servers; dat valt met een factor negen (Intel) en zeven (AMD) terug. Dit is precies gelijk aan de core/bus-ratio.
Opmerkelijk is dat de systeemprestaties voor beide processoren zeer slecht zijn wanneer verschillende werktaken informatie delen. Bij dit onderdeel van de test gebruiken de werktaken een gemeenschappelijke buffer, waar steeds meer in gelezen en geschreven wordt naarmate deze werktaken oplopen. Met een schrijvende thread op een enkele core is de belasting daarvan in Windows Taakbeheer 100 procent. Het prestatieniveau lijkt op dit moment van de test normaal.
Vanuit het perspectief van de applicatiebeheerder of programmeur is de verwachting dat de systeemprestatie bij het verhogen van het aantal werktaken lineair oploopt. In werkelijkheid pakt dat heel anders uit: bij het opstarten van de tweede tot aan de zestiende thread laat zowel de Intel- als de AMD-hardware het afweten. De prestaties blijven namelijk gelijk. Opmerkelijk is dat dit in de systeemparameters niet zichtbaar is. Deze laten braaf zien dat bij elke stap een volgende virtuele processor naar 100 procent gaat. Ook het energieverbruik neemt toe. Het prestatieniveau blijft echter hardnekkig laag.
Een verklaring voor de matige prestaties is dat het zogeheten cache coherency protocol het gehele systeem bij deze generatie Intel- en AMD-processoren intern zwaar belast en daarmee de nuttige werklast in de weg staat. Het cache coherency protocol staat bij de huidige processoren gebruik van een gedeeld buffer pas toe na het legen van alle caches die nog modificaties voor dit stukje geheugen hebben. Deze aanpak waarborgt de data-integriteit in het hoofdgeheugen, maar hindert dus het prestatieniveau. Het legen van de cache is namelijk een relatief tijdrovend proces.
Deze hindering is een gevolg van de architectuurkeuze dat elke core een eigen cache heeft. Een oplossing komt in nieuwe varianten, waarbij het cachegeheugen over meerdere kernen verdeeld wordt zodat het lezen en schrijven naar dit tussengeheugen asynchroon verloopt. Intel gebruikt deze opzet in aanstaande processoren: Woodcrest voor servers met twee sockets en Tigerton voor machines met meer dan twee sockets.
Toekomstige ontwikkelingen
De verwachting is dat beide processorproducenten in volgende generaties chips een betere integratie bewerkstelligen. Dit houdt een koppeling in van cache, interne buffers, floating point rekeneenheden en andere voorzieningen die de verschillende cores met elkaar moeten delen. Een voorproefje hiervan is de integratie in de lap-topprocessor Centrino Duo (met de codenaam Yonah). Deze chip uit de Intel-stal is specifiek ontworpen voor dualcore en gebruikt dan ook een tussen cores gedeelde cache met een dynamische scheiding naar gelang de werklast.
De komende jaren zal het aantal cores per processor snel toenemen. Dat is al te zien in de Sun T1-serverprocessor die onder de codenaam Niagara is ontwikkeld. Deze UltraSparc-variant heeft acht processorkernen in één behuizing, waarbij elke kern vier threads aankan. De chip levert daarmee 32 virtuele processoren aan Suns besturingssysteem Solaris. Intel en AMD zullen een soortgelijk pad volgen om deze mogelijkheden ook aan Windows en Linux te geven. Voor beide processorfabrikanten is de ontwikkeling van energiezuinige chips een opvallende tweede doelstelling naast prestatieverbetering.
Systemen met dualcore processoren verbruiken vijftig procent meer energie. Een dualcore Intel Xeon verbruikt momenteel 150 Watt. Een dualcore dualprocessor (DP) 1U-server, zoals de Dell 1850 bladeserver, verbruikt bij volledige belasting dus meer dan 300 Watt. Een 19-inch rack dat 24 of meer van deze bladeservers huisvest, verstookt meer dan 7000 watt. Dat gaat bestaande airco-voorzieningen wellicht te boven.
Een ander ‘kwetsbaar’ punt is de hedendaagse software. Die is momenteel meestal nog niet geschikt om meerdere kernen optimaal aan te spreken. De cores werken alleen (bijna) optimaal als de werklast door middel van meerdere threads gelijktijdig en gelijkmatig kan worden verdeeld. Een programma dient dus meerdere ‘hoofd-threads’ te gebruiken om de hardware optimaal te benutten. Dit is echter nog lang niet voor alle programmatuur ingevoerd. Zware toepassingen, zoals SQL-databases en mailservers, werken intern al wel parallel omdat zij geschikt gemaakt zijn voor multiprocessor-servers.
Het zal naar verwachting nog vele jaren duren voor de software-industrie alle software geschikt heeft gemaakt voor de nieuwe generatie(s) processoren.



