

Iedereen heeft inmiddels de mond vol van big data. Met de dag groeit het besef van de waarde van data. De nieuwe olie voor organisaties. Of anders gezegd een belangrijke asset die organisaties enorm veel kansen biedt. Tot zover niets nieuws onder de zon. Parallel aan deze ontwikkeling groeit ook het besef dat de waarde van data wordt bepaald door de kwaliteit ervan. Kortom, ook datakwaliteit staat weer hoog op de agenda.
Toch moeten we helaas constateren dat talrijke initiatieven om de kwaliteit van gegevens te verbeteren, stranden. Sterker nog, datakwaliteit blijkt veelal een bottleneck te zijn voor effectieve inzet van data voor organisatiesucces. Hoe datakwaliteit als bottleneck te transformeren naar een bruggenbouwer tussen business en it? Het hulpmiddel is voorhanden.
Samenwerking tussen business en ict
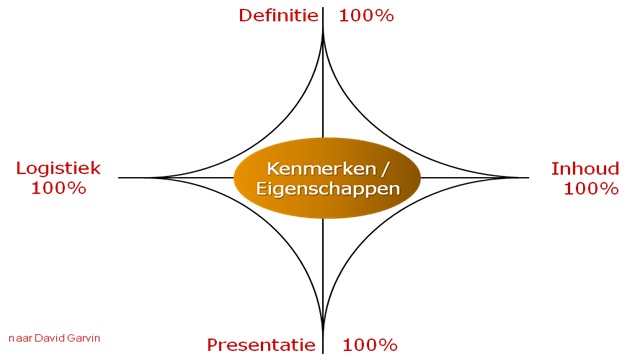
We weten dat samenwerking tussen business en ict nog altijd een uitdaging is. Verschillende belangen, andere taal en een andere cultuur zijn herkenbare verklaringen. Het ontbreken van een adequate ict-governance is veelal de bepalende factor voor het gebrek aan effectieve samenwerking. Wie is verantwoordelijk voor wat? En wie kun je daar vervolgens op aanspreken? Zo wordt de verantwoordelijkheid voor het beheer van datakwaliteit veelal geïnitieerd vanuit een ict-perspectief. Dat is vaak gedoemd te mislukken. Juist nu wanneer data nieuwe, grote kansen biedt, worden de effecten van deze problematiek uitvergroot. Een eenvoudig model helpt niet alleen te bepalen wat de gewenste datakwaliteit moet zijn, maar kan ook business en ict bij elkaar brengen:
Nevenstaand model onderscheidt vier aspecten van data. Afhankelijk van de situatie kan hiermee het gewenste kwaliteitsniveau worden bepaald:
– Definitie – heeft betrekking op de beschrijving van een gegeven: technisch en functioneel. Naast attribuuttype en -lengte is een eenduidige beschrijving van de functie van desbetreffend attribuut van belang;
– Inhoud – verwijst naar de gegevens zelf, de daadwerkelijke bouwstenen voor informatie;
– Presentatie – betreft de weergave van gegevens en de middelen voor deze weergave, zoals tooling voor rapportage;
– Logistiek – is van toepassing op het transport van gegevens en hun beschikbaarheid; ook de middelen die hiervoor worden ingezet vallen onder ‘Logistiek’, zoals de technische infrastructuur.
Meer gedetailleerde specificaties per aspect maken de kwaliteitsdefinities nog specifieker.
Mate van flexibiliteit
Afhankelijk van type proces en organisatie, kan voor elk aspect het vereiste kwaliteitsniveau in kaart worden gebracht. Per aspect kun je het niveau bepalen aan de hand van kenmerken zoals consistentie, compleetheid en correctheid, et cetera.
De mate van flexibiliteit wordt bepaald door de hoeveelheid kenmerken, combinaties daarvan of het toekennen van bedrijfsspecifieke aspecten. De definitie van ‘goed’ en ‘kwaliteit’ kan dus per situatie verschillen. Dat is erg afhankelijk van de functie die gegevens hebben of moeten krijgen in een organisatie. Gegevens zijn van goede kwaliteit als ze voldoend aan gestelde requirements.
Taken, bevoegdheden en verantwoordelijkheden
Wie heeft nu welke taak, bevoegheid en verantwoordelijkheid bij het op orde brengen van de datakwaliteit? Twee voorbeelden:
– De business is primair verantwoordelijk voor de definitie en de inhoud van gegevens. De business zorgt voor een eenduidige definitie die door de gehele organisatie gedragen wordt. En consequent en consistent wordt toegepast. Daarnaast zorgt de business voor de juiste inhoud, in overeenstemming met de requirements.
– Logistiek en presentatie is de primaire verantwoordelijkheid van ict. De ict-afdeling kan worden aangesproken op het tijdige transport, beschikbaarheid en toegankelijkheid van data. Ook de (rapportage)vorm waarin gegevens beschikbaar komen, is voor rekening van ict. Een ‘etl-straat’ zorgt voor een veilig en foutloos transport van gegevens, zodat deze tijdig op de juiste plaats beschikbaar zijn. Ook de fysieke beveiliging van de infrastructuur en in het bijzonder van de diverse gegevensdragers is voor ict een essentieel onderdeel van hun verantwoordelijkheden.
Dit zijn slechts een paar voorbeelden. Gezien de vele mogelijkheden die het model biedt, zijn legio andere situaties denkbaar. Zoals het beveiligings- en autorisatievraagstuk. Het model is een uitgangspunt ofwel een referentiekader. En kan als katalysator het bewustwordingsproces in gang zetten.
Dit proces moet uiteindelijk resulteren in een bedrijfsbreed gewortelde ‘mindset’. Daarmee wordt het streven naar optimale gegevenskwaliteit iets vanzelfsprekends. Volledig ingebed in de dagelijkse handel en wandel van de verschillende organisatiedisciplines.
Datakwaliteit de bruggenbouwer
Uiteraard is er veel meer nodig dan een model. Dat begint bij de onderkenning van het probleem. En het commitment van zowel de business als ict om gezamenlijk tot een oplossing te komen. Als data wordt ervaren als strategische asset, zou dat commitment geen enkele discussie mogen zijn. Dan is het prettig om bovengenoemde methodiek toe te passen die samenwerking tussen business en ICT verder optimaliseert. Datakwaliteit is dan niet langer meer een bottleneck voor business en ict maar een belangrijke bruggenbouwer voor het succes van de samenwerking. En belangrijker nog, een alles bepalende succesfactor voor de effectieve inzet van data!
Arend Jan Kolthof, senior bi-architect bij Sogeti
BI Symposium
Meer weten? Kom dan 25 en 26 november 2013 naar het Spant in Bussum voor het grootste Business Intelligence symposium van ons land.




Dit artikel bevat twee stellingen waar ik wat aan wil toevoegen.
1. “Als data wordt ervaren als strategische asset, zou dat commitment [van zowel de business als ict] geen enkele discussie mogen zijn.” Mee eens, het samenwerken is hier cruciaal. En dan niet op de klassieke ‘over de muur’ manier maar wel ieder zijn eigen rol laten spelen en dit gezamenlijk uitwerken. Dat brengt mij vervolgens bij een tweede stelling:
2. “Ook de (rapportage)vorm waarin gegevens beschikbaar komen, is voor rekening van ict”. Hier ben ik het niet mee eens en hier gaat het in de praktijk ook vaak fout. Deze werkwijze leunt nog veel te sterk op het klassieke BI waarbij de end user niet of nauwelijks in staat is zelf met alle beschikbare data aan de slag te gaan maar alleen bewerkte resultaten krijgt. Een gevolg is o.a. dat het ons honderden miljoenen spreadsheets heeft opgeleverd die nu zoals Felienne Hermans dat mooi zegt de ‘dark matter of IT’ zijn. ICT moet er voor zorgen dat beschikbare onbewerkte juist, tijdig, volledig en betrouwbaar is maar moet niet op de stoel van de inhoudelijk specialist gaan zitten hoe dit te bewerken of te presenteren. Dat moeten ze vooral zelf bedenken en het ook eenvoudig zelf kunnen doen, al dan niet interactief en visueel gemaakt. Het succes van tools als Tableau bewijst m.i. dat dit ook heel goed werkt. ICT moet vooral helpen data te (kunnen) gaan gebruiken.
Ten aanzien van de kwaliteit van data: We hebben in het big data tijdperk inmiddels ook andere mogelijkheden dan vroeger om uitspraken te doen (ook predictive) waarbij de data soms niet zo goed is of niet volledig. De transitie van BI naar Data Science (en dit is echt geen oude wijn in een nieuwe zak) zal de nodige tijd kosten. Daarbij is het alle hens aan dek, voor de business en voor ICT.
Kwaliteit hangt dus af van definitie, inhoud, presentatie en logistiek ?
Als ik goed begrijp is bij bigdata de gegevensverzameling zo groot dat deze niet met traditionele methoden kan worden verwerkt. Definitie en inhoud lijkt me dan alvast best onduidelijk. Dan kan je nog zo fijn presenteren en mooie infrastructuur hebben.
Gelukkig hebben ICT en business een andere taal en cultuur, lees ik, dus is bovenstaande geen enkel probleem 😉
“Ook de (rapportage)vorm waarin gegevens beschikbaar komen, is voor rekening van ict”: de stelling van Oscar Wijsman vraagt om een korte reactie. ‘Presentatie’ heeft betrekking op de rapportagefaciliteiten en de beschikbaarheid en het functioneren hiervan. Wellicht had ik dit explicieter moeten verwoorden. Ik onderschrijf zijn stelling, dat ICT niet op de stoel van de inhoudelijke specialist moet gaan zitten. Deze dient ook naar mijn mening over de geschetste autonomie te beschikken, waarbij ICT een faciliterende rol heeft.
‘Definitie’, ‘inhoud’, ‘presentatie’ en ‘logistiek’ beschrijf ik in mijn artikel als aspecten van data, die inderdaad bepalend kunnen zijn voor de kwaliteit van die data. Dit blijft het geval met de komst van big data. Dat gegevenskwaliteit dan misschien moeilijker is te definiëren of te managen, verandert hieraan niets. Het eventueel verdwijnen van traditionele methoden evenmin. Sterker nog: ‘definitie’ en ‘inhoud’ verdienen nu juist extra aandacht, willen organisaties van de toegevoegde waarde van big data kunnen profiteren. Ogenschijnlijke complexiteit is een slechte reden om op voorhand af te zien van de mogelijkheden zoals ik die voor dit model zie.